深度學習_(時間)序列模型筆記(RNN,BPTT)_常見的序列模型、循環神經網路的分類、根據時間反向傳播
序列模型
- 比方以下一些句子用詞含意,會因為在不同語意場景中,都需要根據上下文來解讀。
- 需要結合前後數據進行分析的類型就稱做序列。
我要去'掛'號看醫生。(預約看診)
你有沒有'掛'失手機?(報失)
新年時家裡都會'掛'燈籠。(懸掛裝飾)
我肚子不舒服,要去"方便"一下。(這裡的"方便"指的是上廁所)
你什麼時候"方便"?我們可以約出來見個面。(在這裡,"方便"指的是有空的時候。)
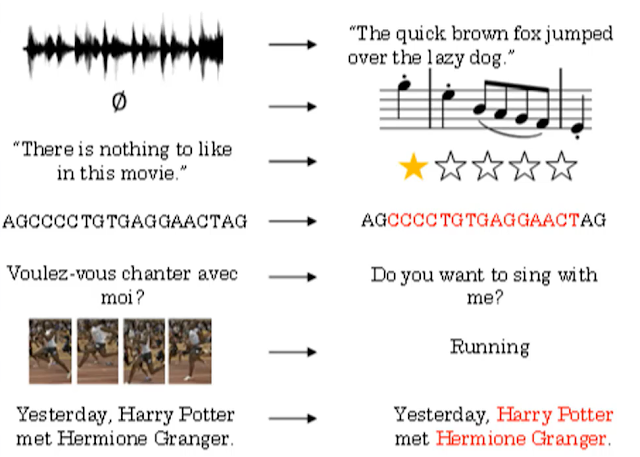
常見的序列模型
- 聲音(音波)
- 影片
- 情感分析(句子文本之間)
- 基因序
- 動作識別
time step(時間步)
- 序列中每個基礎的數據單位
- 每一個時間步都是由多個特徵組成(每個時間步的特徵數量也必相同。)
- 每個序列時間步長度不同
- 每個時間步中根據先後出現時間有各自的編號。
循環神經網路被發展出來的原因?
傳統神經網路或捲積神經網路,它們缺點是無法將特徵分享到不同位置上,也無記憶能力。
所謂無記憶能力也可以理解為,當前時刻的輸出和下一時刻的輸入,它們之前無關係。
每次輸入的數據,其time step與數據長短會不一致。

循環神經網路RNN(Recurrent Neural Network)
Recurrent Neural Network Model用於解決序列問題、處裡序列資料(Sequence Data)的神經網路
比方:自然語言、和時間順序有關的股價預測...等等
想像一下在騎車、開車時候,會考慮不同位置、移動速度的行人、汽機車在未來時間點產生的變化,再去決定前進的路,這是人類大腦根據序列關係所做出之判斷。
優點:
參數共享(整個模型共享同一套參數)
每一時刻皆有輸出
特性:
中間隱藏層具備了循環機制
循環神經網路傳播過程
當第一個被轉換成機器可以讀的向量時,隨後RNN逐個處理向量序列。

隱藏狀態也就充當了神經網路記憶單元,包括網路之前所見過的數據資訊。


接續對隱藏狀態做處理,輸入和先前隱藏狀態組合成的向量。
向量會涵蓋當前輸入(底下)跟先前輸入(左邊進來)的資訊
向量會涵蓋當前輸入(底下)跟先前輸入(左邊進來)的資訊
向量經過激活函數tanh之後,輸出最新的隱藏狀態(網路記憶)。





循環神經網路梯度分析與計算

循環神經網路前向(正向)邏輯

- 底下的X<1> ~ X<T>就代表著數據的輸入,若為句子情境就代表該句子拆分成每個單詞。
- a<0>代表當前時刻隱藏層狀態資訊
- a<1>則是下一個時刻隱藏層資訊
- Wx :a<t-1> 跟a<t>各自前面搭配係數,代表著輸入的權重矩陣
- Wy:代表輸出的權重矩陣
- Wa:連接之前time step跟下一個time step隱藏狀態的權重矩陣。
計算原理如下:

權重矩陣調整計算公式
En對Yn去求偏導數

根據時間反向傳播(Backpropagation Through Time,BPTT)
- 一種RNN中的反向傳播應用
- 將循環神經網路計算圖,依照時間步驟逐次展開time step。
- 根據鍊式法則,應用反向傳播來去計算並儲存相應梯度
RNN存在的問題
- 當反向傳播超過10個時間步,則梯度會變十分小,近似於零甚至消失。此時可能模型還沒優化
- 由於迭代運算處理,也可能面臨梯度爆炸問題,當求的梯度十分大時後,會讓梯度愈來愈大。導致無法優化模型。
循環神經網路的分類
(根據輸出方式分類)
一對多模型(one to many)
輸入一個time step,輸出多個time step資訊
應用:
唐詩處理
音樂生成器(對音樂譜曲)

多對一模型(many to one)
輸入多個time step,輸出一個數據資訊
應用:
文本分類(新聞類型分類->經濟、體育、氣象、政治)
情感分析(分類->正面/反面)
輿情分析

多對多模型(非同步、延時)
輸入多個time step,輸出多個time step資訊
應用:
語音轉文字
機器翻譯

多對多模型(同步、即時)
輸入多個time step,輸出多個time step資訊
應用:
影片分類處裡

PyTorch 神經網絡子模組建立RNN模型
#coding:utf-8 import torch import torch.nn as nn #導入 PyTorch 的神經網絡子模組 class RnnModel(nn.Module): def __init__(self): super(RnnModel,self).__init__() self.rnn = nn.RNN(input_size=1, hidden_size=32, num_layers=1)#輸入特徵的維度是 1,隱藏層的維度是 32,網絡中只有一層 RNN self.out = nn.Linear(32,1)#建立一個線性層,用於將 RNN 的輸出維度從 32 轉換到 1,即網絡的最終輸出維度。 def forward(self,x,h):#定義模型的前向傳播函數,x 是輸入數據,h 是隱藏狀態。 out,h = self.rnn(x,h)#通過 RNN 層進行計算,獲取當前輸出和新的隱藏狀態。 prediction = self.out(out)#將 RNN 的輸出通過線性層,獲得最終的預測結果。 return prediction,h rnn = RnnModel() print(rnn)#打印模型結構。

可以看到其網路結構輸出
輸入層一個神經網路數量(輸入特徵的維度是 1),而隱藏層為32個單元。
上一個時刻的輸出也就是當前時刻的輸入,因此in_feature為32。
而out_feature為1個模型的輸出。(比方0/1正反面情感分析)
PyTorch 透過交叉墒完成反向傳播運算處理
#coding:utf-8 import torch x = torch.ones(5) # 輸入資料 創建一個元素全為 1,長度為 5 的張量,用來作為輸入數據。 y = torch.zeros(3) #輸出資料 創建一個元素全為 0,長度為 3 的張量,用來作為目標輸出數據。 w = torch.randn(5,3,requires_grad=True)#創建一個形狀為 5x3 的權重張量,初始化為隨機值。requires_grad=True 指定 PyTorch 在反向傳播時需要計算這個張量的梯度。 b = torch.randn(3,requires_grad=True)#創建一個長度為 3 的偏差張量,初始化為隨機值,並設置為需要計算梯度。 z = torch.matmul(x,w) + b#使用矩陣乘法將輸入 x 與權重 w 相乘,然後加上偏差 b,得到輸出張量 z。 loss = torch.nn.functional.binary_cross_entropy_with_logits(z,y)#計算 z 和 y 之間的二元交叉熵損失。這個損失函數適用於二分類問題 print("z的梯度函數為:" , z.grad_fn) print("loss的梯度函數為:" , loss.grad_fn) loss.backward()#進行反向傳播計算,通過這個過程計算損失對權重 w 和偏差 b 的梯度。這行若註解掉底下就輸出都會為none print(w.grad) print(b.grad)




留言
張貼留言