LLM及LangChain開發筆記(1)_LangChain與LLM觀念與相關術語簡介Chains(鏈)跟Prompts(提示)


LangChain 由 Harrison Chase 創建,是一個 Python 庫,為使用 LLM 構建 NLP 應用程式提供開箱即用的支援。
可以連接到各種數據和計算源,並構建在特定於域的數據源、私有存儲庫等上執行 NLP 任務的應用程式。
LangChain與LLM有何區別?
LLM(大語言模型): 是一類具有巨大規模和緊急功能的語言模型。
LLM 是 LangChain 的基本組成部分。它本質上是大型語言模型的包裝器,有助於使用特定大型語言模型的功能和能力。
LangChain 是一個用於創建由語言模型驅動的應用程式的框架,但並非統包概念,仍然拆分很多零散的套件。最新版出到0.3版本,不同版本上下支援度也會有落差。
LangChain 中的一些模組:
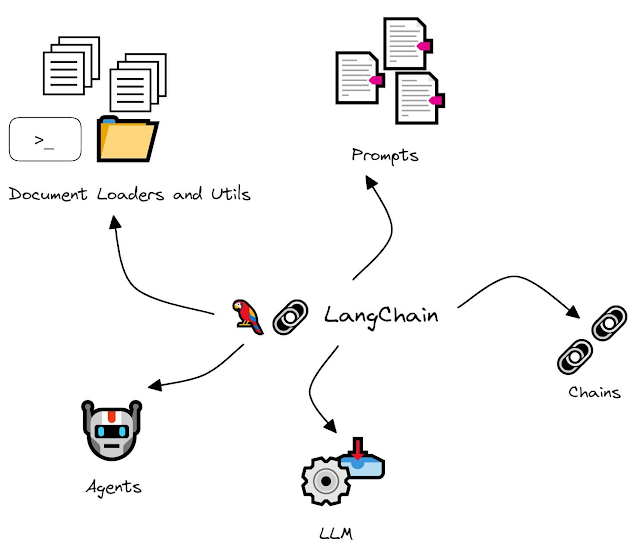
LangChain 有6大核心模塊(除了LLM Model之外另外5個):
- Models:從不同的LLM和嵌入模型中進行選擇
- Prompts:管理LLM輸入
- Chains:將LLM與其他組件組合
- Document Loaders and Utils/Tools:訪問外部數據
- Memory:記住以前的對話
- Agents:訪問其他工具
Prompts (提示)
提示是任何 NLP 應用程式的核心。即使在 ChatGPT 運作階段,答案的幫助也取決於提示。
為此,LangChain 提供了可用於格式化輸入和許多其他實用程式的提示範本。
Chains (鏈)
LLM 是 LangChain 中的基本單元。而LangChain可以根據特定任務將 LLM 調用連結在一起。
例如,您可能需要從特定 URL 獲取數據,匯總返回的文字,並使用生成的摘要回答問題。
鏈也可以是較簡單的作業模式,比方可能需要讀入使用者輸入,然後使用該輸入來構建提示。在使用該 API 來生成回應。
Document Loaders and Utils(文件載入器和相關工具應用)
提供模型可使用的外部功能,如查詢資料庫、調用外部 API 等,擴展模型的能力範圍。
LangChain 的 Document Loaders 和 Utils 模組分別有助於連接到數據源和計算源。
假設您有大量經濟學文本,您想在其上構建一個 NLP 應用程式。您的語料庫可能是文本檔、PDF 文檔、HTML 網頁、圖像等的混合體。目前,文檔載入程式利用 Python 庫 Unstructured 將這些原始數據源轉換為可處理的文本。
Unstructured
DocumentLoader:載入文件(PDF, txt, web, etc.)
TextSplitter:切分長文本為段落
VectorStore:將文本轉為向量並儲存(如 FAISS, Chroma, Pinecone)
Retriever:根據 query 抽出相關文檔段落
Memory(記憶模組)
儲存對話歷史,使模型能夠回顧上下文,能夠在多輪對話中保持連貫性。
記憶類型:
ConversationBufferMemory:儲存整段對話
SummaryMemory:將歷史對話摘要再餵給模型
VectorStoreRetrieverMemory:將對話儲存成向量,便於查找
Agents (代理)
整合 Tools 使模型能夠與外部環境互動,如調用 API 或執行特定操作,提升應用的靈活性。實現代理機制的應用。
「chains」 可以説明將一系列 LLM 調用連結在一起。但是,在某些任務中,調用的順序通常不是確定性的。下一步可能取決於使用者輸入和前面步驟中的回應。
對於此類應用程式,LangChain 庫提供了 「Agents」,它可以根據沿途的輸入而不是硬編碼的確定性序列來執行作。
除了上述功能外,LangChain 還提供與向量資料庫的整合,並具有用於維護 LLM 調用之間狀態的記憶體功能等等。
Ref:
https://www.kdnuggets.com/2023/04/langchain-101-build-gptpowered-applications.html



留言
張貼留言