將地端原先在IIS跑的 .net6 mvc專案給deploy到ec2 linux Apache主機上

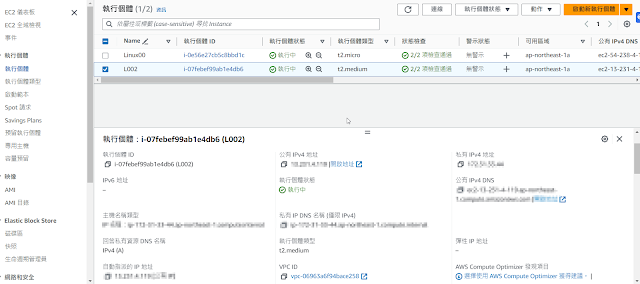
假設你已經完成上一篇介紹的諸多處理前置流程後 Linux上安裝SQL Server 將地端MSSQL資料庫移轉至aws ec2主機上的MSSQL 通常你應用程式中的appsettings.json一些資料庫連線配置 要注意需要微調 Server: 將 .\\SQLEXPRESS 更改為您的EC2實例的公共IP或DNS名稱。 Database: 如果您的資料庫名稱仍然是 BingoDb,則不需要更改。 Trusted_Connection: 由於您正在使用SQL Server身份驗證(User ID和Password),您可能需要從連接字符串中刪除 Trusted_Connection=True;。 TrustServerCertificate: 如果您的EC2 SQL Server使用的是自簽名證書,則保留此選項。如果不是,您可能想刪除它。 User ID 和 Password: 確保這些是您在EC2 SQL Server上設定的憑證。 "ConnectionStrings": { "MyDbConn": "Server=YOUR_EC2_PUBLIC_IP_OR_DNS;Database=BingoDb;TrustServerCertificate=true;MultipleActiveResultSets=true;User ID=xxx;Password=YOUR_PASSWORD" } 請將 YOUR_EC2_PUBLIC_IP_OR_DNS 替換為您EC2實例的實際公共IP或DNS,並將 YOUR_PASSWORD 替換為實際的 xxx 密碼。 實際拿地端專案整合連線看看會發現出現錯誤 Microsoft.Data.SqlClient.SqlException: 'Login failed. The login is from an untrusted domain and cannot be used with Integrated authentication.' 可能原因在於從一個不同的域連接到SQL Server有關。當在本地開發時,集成身份驗證很好用,因為您的開發機器和SQL Server通常位於同一域或工作組中。 但是,當您將SQL Server移到遠程主機(如EC...