資料探勘研究與實務_空氣品質預報Time Series Regression_part1

下載資料集
新竹地區2021年10~12月之空氣品質資料

預設載下來是一個CSV
第一行之"0"~"23"代表小時。
那這次作業給的檔案還滿混亂的
首先測項不僅PM2.5而是混雜著其他項目
再來時間區段是跨好幾個月份2021的1月到12月
# 表示儀器檢核為無效值,* 表示程式檢核為無效值,x 表示人工檢核為無效值,A 係指因儀器疑似故障警報所產生的無效值,空白 表示缺值。
然後還是一個.xls檔案

在一開始讀取時要指定engine為xlrd
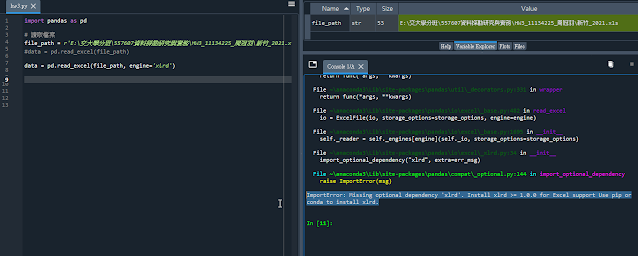
若沒特別指定此時可能會報以下的錯
ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.
假設你指定了仍報錯,就需要再補pip install一下。
在Spyder中要補其他套件方式在console下指令即可

看到dataframe讀取進來了真好

第1階段程式碼
1 2 3 4 5 6 | import pandas as pd # 讀取檔案 file_path = r'E:\交大學分班\557607資料探勘研究與實務\HW3_11134225_周冠羽\新竹_2021.xls' data = pd.read_excel(file_path, engine='xlrd') |
資料前處理
a. 取出10.11.12月資料
b. 缺失值以及無效值以前後一小時平均值取代 (如果前一小時仍有空值,再取更前一小時)
c. NR表示無降雨,以0取代
d. 將資料切割成訓練集(10.11月)以及測試集(12月)
e. 製作時序資料: 將資料形式轉換為行(row)代表18種屬性,欄(column)代表逐時數據資料
我們資料剛剛有說過充斥著
# 表示儀器檢核為無效值
* 表示程式檢核為無效值
x 表示人工檢核為無效值
A 指因儀器疑似故障警報所產生的無效值
空白 表示缺值。



第2階段程式碼
資料前處理
a. 取出10.11.12月資料
b. 缺失值以及無效值以前後一小時平均值取代 (如果前一小時仍有空值,再取更前一小時)
c. NR表示無降雨,以0取代
d. 將資料切割成訓練集(10.11月)以及測試集(12月)
e. 製作時序資料: 將資料形式轉換為行(row)代表18種屬性,欄(column)代表逐時數據資料
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import pandas as pd # 讀取檔案 file_path = r'E:\交大學分班\557607資料探勘研究與實務\HW3_11134225_周冠羽\新竹_2021.xls' data = pd.read_excel(file_path, engine='xlrd') # 清理數據:移除不需要的第一橫列,設置正確的列名 data_cleaned = data.iloc[1:] data_cleaned.reset_index(drop=True, inplace=True) correct_hour_columns = ['測站', '日期', '測項'] + [str(i) for i in range(24)] data_cleaned.columns = correct_hour_columns # 轉換日期格式並篩選出10、11、12月的資料 data_cleaned['日期'] = pd.to_datetime(data_cleaned['日期']) data_filtered = data_cleaned[data_cleaned['日期'].dt.month.isin([10, 11, 12])] data_filtered.reset_index(drop=True, inplace=True) |

那這邊缺失值問題需要校正

第3階段程式碼
資料前處理
a. 取出10.11.12月資料
b. 缺失值以及無效值以前後一小時平均值取代 (如果前一小時仍有空值,再取更前一小時)
c. NR表示無降雨,以0取代
d. 將資料切割成訓練集(10.11月)以及測試集(12月)
e. 製作時序資料: 將資料形式轉換為行(row)代表18種屬性,欄(column)代表逐時數據資料
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | import pandas as pd # 讀取檔案 file_path = r'E:\交大學分班\557607資料探勘研究與實務\HW3_11134225_周冠羽\新竹_2021.xls' data = pd.read_excel(file_path, engine='xlrd') # 清理數據:移除不需要的第一橫列,設置正確的列名 data_cleaned = data.iloc[1:].copy() # 使用 .copy() 來創建副本,避免後續操作持續冒出 SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrame. data_cleaned.reset_index(drop=True, inplace=True) correct_hour_columns = ['測站', '日期', '測項'] + [str(i) for i in range(24)] data_cleaned.columns = correct_hour_columns # 轉換日期格式並篩選出10、11、12月的資料 data_cleaned['日期'] = pd.to_datetime(data_cleaned['日期']) #data_filtered = data_cleaned[data_cleaned['日期'].dt.month.isin([10, 11, 12])] # 使用 .copy() 來創建副本,避免後續操作持續冒出 SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrame. data_filtered = data_cleaned[data_cleaned['日期'].dt.month.isin([10, 11, 12])].copy() data_filtered.reset_index(drop=True, inplace=True) # 將 'NR' 替換為 0,然後將 *, #, x 替換為 NaN。 data_filtered.replace({'NR': 0, '*': pd.NA, '#': pd.NA, 'x': pd.NA}, inplace=True) # 確保所有數據列都是數值型 for col in data_filtered.columns[3:]: data_filtered[col] = pd.to_numeric(data_filtered[col], errors='coerce') # 處理缺失值:使用前後一小時的平均值填充缺失值 #對於每個缺失的數據點,我們往前和往後尋找非缺失的值來計算平均值進行填充。如果前面沒有有效值,則僅使用後面的值;如果後面也沒有有效值,則僅使用前面的值。最後,我們檢查整個 DataFrame 確保沒有剩餘的缺失值。 for col in data_filtered.columns[3:]: for i in range(len(data_filtered)): if pd.isna(data_filtered.at[i, col]): # 往前找到非缺失值 prev_index = i - 1 while prev_index >= 0 and pd.isna(data_filtered.at[prev_index, col]): prev_index -= 1 # 往後找到非缺失值 next_index = i + 1 while next_index < len(data_filtered) and pd.isna(data_filtered.at[next_index, col]): next_index += 1 # 計算平均值並填充 prev_val = data_filtered.at[prev_index, col] if prev_index >= 0 else None next_val = data_filtered.at[next_index, col] if next_index < len(data_filtered) else None if prev_val is not None and next_val is not None: data_filtered.at[i, col] = (prev_val + next_val) / 2 elif prev_val is not None: data_filtered.at[i, col] = prev_val elif next_val is not None: data_filtered.at[i, col] = next_val # 檢查是否還有缺失值 missing_values_after_fill = data_filtered.isnull().sum().sum() print(f'After filling, the number of missing values is: {missing_values_after_fill}') |
那在去上一張圖觀察缺失值(*,x# 這些)
另外在進行 DataFrame 的一個切片,當對這樣的切片進行賦值時,可能不會影響原始 DataFrame。
就會報以下錯誤:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
解決這個問題的做法是在進行切片或選擇操作時確保返回的是一個副本。
在賦值之前,我們可以使用 .copy() 來創建一個 DataFrame 的副本,這樣就可以安全地對該副本進行修改而不會收到警告。這通常在對 DataFrame 進行篩選操作之後立即進行。

第4階段程式碼
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | import pandas as pd # 讀取檔案 file_path = r'E:\交大學分班\557607資料探勘研究與實務\HW3_11134225_周冠羽\新竹_2021.xls' data = pd.read_excel(file_path, engine='xlrd') # 清理數據:移除不需要的第一橫列,設置正確的列名 data_cleaned = data.iloc[1:].copy() # 使用 .copy() 來創建副本,避免後續操作持續冒出 SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrame. data_cleaned.reset_index(drop=True, inplace=True) correct_hour_columns = ['測站', '日期', '測項'] + [str(i) for i in range(24)] data_cleaned.columns = correct_hour_columns # 轉換日期格式並篩選出10、11、12月的資料 data_cleaned['日期'] = pd.to_datetime(data_cleaned['日期']) #data_filtered = data_cleaned[data_cleaned['日期'].dt.month.isin([10, 11, 12])] # 使用 .copy() 來創建副本,避免後續操作持續冒出 SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrame. data_filtered = data_cleaned[data_cleaned['日期'].dt.month.isin([10, 11, 12])].copy() data_filtered.reset_index(drop=True, inplace=True) # 將 'NR' 替換為 0,然後將 *, #, x 替換為 NaN。 data_filtered.replace({'NR': 0, '*': pd.NA, '#': pd.NA, 'x': pd.NA}, inplace=True) # 確保所有數據列都是數值型 for col in data_filtered.columns[3:]: data_filtered[col] = pd.to_numeric(data_filtered[col], errors='coerce') # 處理缺失值:使用前後一小時的平均值填充缺失值 #對於每個缺失的數據點,我們往前和往後尋找非缺失的值來計算平均值進行填充。如果前面沒有有效值,則僅使用後面的值;如果後面也沒有有效值,則僅使用前面的值。最後,我們檢查整個 DataFrame 確保沒有剩餘的缺失值。 for col in data_filtered.columns[3:]: for i in range(len(data_filtered)): if pd.isna(data_filtered.at[i, col]): # 往前找到非缺失值 prev_index = i - 1 while prev_index >= 0 and pd.isna(data_filtered.at[prev_index, col]): prev_index -= 1 # 往後找到非缺失值 next_index = i + 1 while next_index < len(data_filtered) and pd.isna(data_filtered.at[next_index, col]): next_index += 1 # 計算平均值並填充 prev_val = data_filtered.at[prev_index, col] if prev_index >= 0 else None next_val = data_filtered.at[next_index, col] if next_index < len(data_filtered) else None if prev_val is not None and next_val is not None: data_filtered.at[i, col] = (prev_val + next_val) / 2 elif prev_val is not None: data_filtered.at[i, col] = prev_val elif next_val is not None: data_filtered.at[i, col] = next_val # 檢查是否還有缺失值 missing_values_after_fill = data_filtered.isnull().sum().sum() print(f'After filling, the number of missing values is: {missing_values_after_fill}') #根據月份將資料分成訓練集(10月和11月)和測試集(12月) train_data = data_filtered[data_filtered['日期'].dt.month.isin([10, 11])] test_data = data_filtered[data_filtered['日期'].dt.month == 12] #將訓練集的資料轉換成時序資料,其中行代表18種屬性,列代表每小時的數據。 # 首先我們需要確定屬性的唯一值 unique_items = train_data['測項'].unique() # 建立一個空的DataFrame來保存時序格式的數據 time_series_data = pd.DataFrame() # 對於訓練集中的每一種屬性 for item in unique_items: # 挑選出該屬性的所有行 item_data = train_data[train_data['測項'] == item].iloc[:, 3:].reset_index(drop=True) # 由於每一天的數據在單獨的行中,我們需要將它們連接起來 item_data = item_data.melt(var_name='hour', value_name=item) # 重排列索引,使其成為連續的時序數據 item_data = item_data.sort_values(by='hour').reset_index(drop=True) time_series_data[item] = item_data[item] # 設定正確的行索引 time_series_data.index = pd.date_range(start=train_data['日期'].min(), periods=len(time_series_data), freq='H') # 現在,time_series_data 已經是一個時序資料集,行代表時間,列代表18種屬性的測量值 print(time_series_data.shape) # 應該是 (18, 61*24) 如果包括10月和11月的所有小時 # 檢查維度是否符合預期(應該有61天*24小時=1464個時刻) #assert time_series_data.shape == (1464, len(unique_items)), "維度不匹配" |
資料前處理
a. 取出10.11.12月資料
b. 缺失值以及無效值以前後一小時平均值取代 (如果前一小時仍有空值,再取更前一小時)
c. NR表示無降雨,以0取代
d. 將資料切割成訓練集(10.11月)以及測試集(12月)
e. 製作時序資料: 將資料形式轉換為行(row)代表18種屬性,欄(column)代表逐時數據資料




以上是資料前處理階段



留言
張貼留言