Python_Exception例外異常處理_with語法使用教學介紹
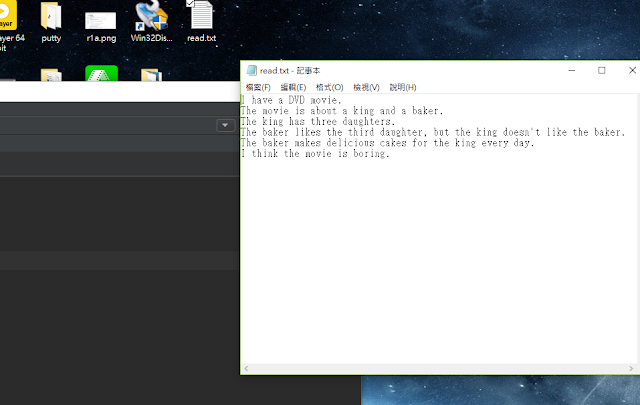
在寫任何程式過程中難免會出現一些例外 (異常) python 也是如此 為此python提供了 Exception 解決的語法方案 讓我們先來簡單示範一下讀取一個文字檔案中的內容 先準備一個文字檔案 內容中有 取名為read.txt 然後放在桌面 和 C槽 寫一個簡單的 openfile的python程式 再輸入路徑之後 你感覺程式運行都很正常 但是一般用戶可能會忽略 .txt副檔名 就會出現這個異常 FileNotFoundError的異常錯誤 這是一個系統子類之異常 Python常見的異常 (摘錄自:http://www.runoob.com/python/python-exceptions.html) 異常名稱 描述 BaseException 所有異常的基類 SystemExit 解釋器請求退出 KeyboardInterrupt 用戶中斷執行(通常是輸入^C) Exception 常規錯誤的基類 StopIteration 迭代器沒有更多的值 GeneratorExit 生成器(generator)發生異常來通知退出 StandardError 所有的內建標準異常的基類 ArithmeticError 所有數值計算錯誤的基類 FloatingPointError 浮點計算錯誤 OverflowError 數值運算超出最大限制 ZeroDivisionError 除(或取mode)零(所有數據類型) AssertionError 斷言語句失敗 AttributeError 對像沒有這個屬性 EOFError 沒有內建輸入,到達EOF 標記 EnvironmentError 操作系統錯誤的基類 IOError 輸入/輸出操作失敗 OSError 操作系統錯誤 WindowsError 系統調用失敗 ImportError 導入模塊/對象失敗 LookupError 無效數據查詢的基類 IndexError 序列中沒有此索引(index) KeyError 映射中沒有這個鍵 MemoryError 內存溢出錯誤(對於Python 解釋器不是致命的) NameError 未聲明/初始化對象(沒有屬性) UnboundL...