Virtual Assistant 運作模式探討_TTS和STT的原理及運作Keep It Simple, Stupid
Virtual Assistant 從字面上來翻譯叫做虛擬助理

在商業電影中 鋼鐵人等科幻片
很常有向電腦說話溝通就自動有服裝換上或是飲料遞送而來的畫面
讓人覺得十分特別
Commercial Virtual Assistants
其實在許多手機 Siri 語音助理就時常看到
FB創辦者 Mark Zuckerberg 近期的 Jarvis
就是一個很生活化又典型的例子
當中運用到了
TTS 及 STT 兩項技術
TTS (Text-to-Speech)
STT(Speech-to-Text)
基本上和使用者的人機互動模式為
STT(Speech-to-Text)
Input端為人說的話語
透過STT技術轉為字串,才可讓邏輯引擎去做處理。
當中用到了 Natural Language Processing(NLP) 來轉換語音字串
當然這些錄音資料會有去噪和修復扭曲的前置處理,才可讓電腦能夠做語音轉字串處裡。
Logic Engine
主要就是接收人的語音訊息,再丟給電腦做聲紋之類的分析
最終目標是去判斷要回應捨麼內容(Output為何??)
可以說是大腦的部分
TTS (Text-to-Speech)
之後接收來自邏輯引擎回傳的資訊
將要回應的文字字串轉為語音資訊
以下我們用 樹梅派 來嘗試開發這套簡單小系統
首先至下方兩個網站
下載 PortAudio 及 PyAudio
(前提是你的Alsa的相關設定都已經就緒)
因為 PortAudio 的驅動和 ALSA 密切相關
若還未設定就下看看如下指令
sudo apt-get install libasound-dev
後續可參考下方link
參考 link
http://cagewebdev.com/raspberry-pi-getting-audio-working/
http://karuppuswamy.com/wordpress/2015/08/15/configuring-alsa-audio-output-on-analog-and-hdmi-of-raspberry-pi/
第二階段 . 下載並安裝 PortAudio 及 PyAudio
PortAudio
www.portaudio.com/download.html

下載完之後你應該要先行解壓縮
之後將解壓後的Folder "portaudio"
放置於 /home/pi目錄下
在用下面這行指令做編譯才能用喔
./configure && make
執行 configure 來建立 Makefile , 這個步驟成功之後
再以 make 來呼叫所需要的資料來編譯即可
捨麼是make指令呢????
(若是 Linux 初學者)
講白話一些就是你在網路上下載來的這種軟體套件工具Library
都必須先做compiling 轉為 機械碼
讓電腦知道有新的東西加入至環境中
在 鳥哥 部落格中的更詳盡說明之中
有個示意圖 (摘錄自 : 鳥哥)
一般在 Linux 上面被公認為標準的程式語言 C ,
在撰寫完C Code 之後 此時這裡的原始程式碼 還只是單純的文字檔案
通常會以 Linux 上標準的 C 語言編譯器 gcc 這支程式來編譯轉譯為電腦看的懂的
binary program (可執行檔)

但其實用類似 gcc 的編譯器來進行編譯過程並不簡單
況且一套軟體並不會僅有一支程式, 而是包含一堆程式碼檔案。
所以除了每個主程式與副程式均需要寫上一筆編譯過程的指令外
還需要寫上最終的連結程序
當我們執行 make 時,
make 會在當時的目錄下搜尋 Makefile (or makefile) 這個文字檔
而 Makefile 裡面則記錄了原始碼如何編譯的詳細資訊
make 會自動的判別原始碼是否經過變動了,而自動更新執行檔
一般軟體開發商都會寫一支偵測程式來偵測
1.使用者的作業環境
2.該作業環境是否有軟體開發商所需要的其他功能
當偵測完畢後
就會主動建立 Makefile 的規則檔案
(一般常見偵測程式的檔案名為 configure 或者是 config !!!)
偵測作業環境目的在於判斷
(1)是否有適宜的編譯器可編譯該軟體的程式碼
(2)是否已存有該軟體所需之函式庫 or 其他所需的相依軟體
(3)作業系統平台是否和此軟體有適應,包括 Linux 的核心版本
(4)核心的表頭定義檔 (header include) 是否存在 (驅動程式必須要的偵測)

PyAudio
http://people.csail.mit.edu/hubert/pyaudio/

PortAudio主要是跨平台(Windows 、Unix、OS X) 的控制音檔 I/O 的 OpenSource
可以協助我們後續做Speech-Recognition Module
(支援 CPP、 python等程式語言)
PyAudio 則是 和他有相關的 Python 套件
可以用它去驅使Python 做 語音錄製後的STT後續功能
記得需要用到外接 麥克風音訊裝置(USB音效卡一個)
PyAudio 安裝指令
sudo apt-get install python-pyaudio python3-pyaudio

PortAudio 下載安裝
在你下載好 portaudio 的壓縮檔案後
可先行解壓縮
並切至該檔案夾目錄下
執行編譯的指令
cd portaudio
./configure
make
緊接著
第三階段. 使用密技
SpeechRecognition套件模組的下載
(使用到Google的語音)
這個套件庫支持 Google Speech Recognition
還有 Wit.ai 、AT&T跟 IBM 等公司的音訊資料協助程式設計師可做
語音轉文字功能
pip 指令
pip install SpeechRecognition

然後我遇到了滿江紅 嗚嗚嗚 T T
好想哭 好啦別怕
莫急~
莫荒~
莫害怕~
前面加上 sudo 然後 try again
就可以了喔
第四階段.撰寫python程式驅動錄音
之後就是寫程式的時間
寫完程式運行測試後的結果就是
兩種Error
第一階段的Error測試顯示出
Traceback (most recent call last):
File "speechRecog_Ex1.py", line 1, in <module>
import speech_recognition as sr
ImportError: No module named 'speech_recognition'
這邊透過 alias指令 切換 python目前使用版本
再重新下載 SpeechRecognition 的套件
重新執行

第二階段. Error訊息
Traceback (most recent call last):
File "speechRecog_Ex1.py", line 3, in <module>
with sr.Microphone() as source:
File "/usr/local/lib/python3.4/dist-packages/speech_recognition/__init__.py", line 78, in __init__
self.pyaudio_module = self.get_pyaudio()
File "/usr/local/lib/python3.4/dist-packages/speech_recognition/__init__.py", line 112, in get_pyaudio
raise AttributeError("PyAudio 0.2.9 or later is required (found version {})".format(pyaudio.__version__))
AttributeError: PyAudio 0.2.9 or later is required (found version 0.2.8)
我們剛剛安裝的 PyAudio 版本預設指令安裝到舊版

國外有程式設計師遭遇相同問題並在論壇發問
https://www.raspberrypi.org/forums/viewtopic.php?f=32&t=151200
這裡參考 國外老手的建議
有人說到由於 在Raspberry Pi 的Debian作業系統
目前0.2.8對於此版本系統是最新版本
所以無法靠指令直接快速升級
因此需要手動自行再下載0.2.9官方更新版本
重新編譯才行
不過有老鳥建議這個和我一樣遇到此棘手問題的發問者
先嘗試下看看 三個指令
當然能靠指令完事的是最好的問題解決方案
Keep It Simple, Stupid
Step1.Install portaudio19-dev
sudo apt-get install portaudio19-dev
Step2.Then install PyAudio with pip
sudo pip3 install PyAudio
Step3.If pip for python3 is not installed then install it too
sudo apt-get install python3-pip
試完之後果然一點用也沒有
還是無法運行 依然顯示0.2.9錯誤訊息
QQ
可是 !!!
有人說他下了這個指令之後
sudo pip3 install PyAudio
有顯示如下資訊
pi@raspberrypi:~/src $ sudo pip3 install PyAudio
Downloading/unpacking PyAudio
Downloading PyAudio-0.2.9.tar.gz (289kB): 289kB downloaded
Running setup.py (path:/tmp/pip-build-j2mfdfnj/PyAudio/setup.py) egg_info for package PyAudio
這裡想到一個方式
就是系統更新指令 !!!!
sudo apt-get update
sudo apt-get upgrade
sudo reboot
解決問題的思路
先更新目前作業系統
之後再嘗試剛才有人試成功的指令
嘗試後的結果仍然無法修正版本錯誤
不會自動更新抓新版本的 PyAudio
後來參考此link
https://pypi.python.org/pypi/SpeechRecognition/3.4.3
和非常重要的 pip 升級指令
How can I upgrade specific packages using pip and a requirements file?
https://stackoverflow.com/questions/4536103/how-can-i-upgrade-specific-packages-using-pip-and-a-requirements-file
終於成功修正 PyAudio版本更新問題
指令
sudo pip install pyaudio --upgrade
若有人還是無法
像我第二次在哏市話後重新安裝的系統環境嘗試
此紀錄之方法又有問題
可以試試看另一種方式
修改pip源頭
預設的source為pypi.python.org
修改pip source可以加速模塊的下載,可以大幅提高安裝效率
$ cd
$ mkdir .pip
$ cd .pip
$ vim pip.conf
輸入如下內容保存後退出:
重新執行點下載命令
sudo apt purge python3-pyaudio
sudo apt install portaudio19-dev python-all-dev
sudo pip3 install pyaudio==0.2.9 --upgrade
ref link:
https://askubuntu.com/questions/915227/how-do-i-get-pyaudio-0-2-9-installed-on-ubuntu-16-04
https://lizonghang.github.io/2016/07/30/Python%E5%AE%9E%E7%8E%B0%E5%BD%95%E9%9F%B3%E5%8A%9F%E8%83%BD/
若要查看安裝了哪些 pip 套件
指令
pip list
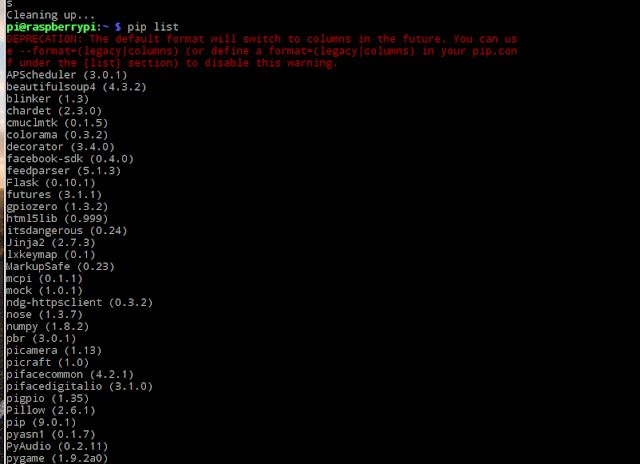

目前最新版已經到 pyAudio 0.2.11
成功執行程式後
我們於終端機Run程式
測試
這次又有新的錯誤是有關於 ALSA的設定問題
Error如下圖顯示


Ref:
ImportError: No module named SpeechRecognition
https://stackoverflow.com/questions/43806542/importerror-no-module-named-speechrecognition
Trouble Getting PyAudio 0.2.9
https://www.raspberrypi.org/forums/viewtopic.php?f=32&t=151200
Error for Pyaudio 0.2.9 version
https://github.com/Uberi/speech_recognition/issues/104
How install pyaudio 0.2.9
https://www.codeproject.com/Questions/1130087/How-install-pyaudio
PortAudio on Raspberry Pi
https://app.assembla.com/wiki/show/portaudio/Platforms_RaspberryPi
Speech Recognition using Google Speech API
https://pythonspot.com/en/speech-recognition-using-google-speech-api/
蓝林鸟的博客 - Portaudio的安装与语音信号采集
http://www.ramlinbird.com/portaudio%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E8%AF%AD%E9%9F%B3%E4%BF%A1%E5%8F%B7%E9%87%87%E9%9B%86/
师母已呆-2015的博客
http://blog.sina.com.cn/s/blog_13d4ad50b0102v7rz.html
PortAudio编程入门 V19
https://my.oschina.net/sulliy/blog/77055
coding portaudio-wavplay-demo.cpp (screen recording)
https://www.youtube.com/watch?v=7f1U6jG3RAw

在商業電影中 鋼鐵人等科幻片
很常有向電腦說話溝通就自動有服裝換上或是飲料遞送而來的畫面
讓人覺得十分特別
Commercial Virtual Assistants
其實在許多手機 Siri 語音助理就時常看到
FB創辦者 Mark Zuckerberg 近期的 Jarvis
就是一個很生活化又典型的例子
當中運用到了
TTS 及 STT 兩項技術
TTS (Text-to-Speech)
STT(Speech-to-Text)
基本上和使用者的人機互動模式為
STT(Speech-to-Text)
Input端為人說的話語
透過STT技術轉為字串,才可讓邏輯引擎去做處理。
當中用到了 Natural Language Processing(NLP) 來轉換語音字串
當然這些錄音資料會有去噪和修復扭曲的前置處理,才可讓電腦能夠做語音轉字串處裡。
Logic Engine
主要就是接收人的語音訊息,再丟給電腦做聲紋之類的分析
最終目標是去判斷要回應捨麼內容(Output為何??)
可以說是大腦的部分
TTS (Text-to-Speech)
之後接收來自邏輯引擎回傳的資訊
將要回應的文字字串轉為語音資訊
以下我們用 樹梅派 來嘗試開發這套簡單小系統
首先至下方兩個網站
下載 PortAudio 及 PyAudio
(前提是你的Alsa的相關設定都已經就緒)
因為 PortAudio 的驅動和 ALSA 密切相關
若還未設定就下看看如下指令
sudo apt-get install libasound-dev
後續可參考下方link
參考 link
http://cagewebdev.com/raspberry-pi-getting-audio-working/
http://karuppuswamy.com/wordpress/2015/08/15/configuring-alsa-audio-output-on-analog-and-hdmi-of-raspberry-pi/
第二階段 . 下載並安裝 PortAudio 及 PyAudio
PortAudio
www.portaudio.com/download.html

下載完之後你應該要先行解壓縮
之後將解壓後的Folder "portaudio"
放置於 /home/pi目錄下
在用下面這行指令做編譯才能用喔
./configure && make
執行 configure 來建立 Makefile , 這個步驟成功之後
再以 make 來呼叫所需要的資料來編譯即可
捨麼是make指令呢????
(若是 Linux 初學者)
講白話一些就是你在網路上下載來的這種軟體套件工具Library
都必須先做compiling 轉為 機械碼
讓電腦知道有新的東西加入至環境中
在 鳥哥 部落格中的更詳盡說明之中
有個示意圖 (摘錄自 : 鳥哥)
一般在 Linux 上面被公認為標準的程式語言 C ,
在撰寫完C Code 之後 此時這裡的原始程式碼 還只是單純的文字檔案
通常會以 Linux 上標準的 C 語言編譯器 gcc 這支程式來編譯轉譯為電腦看的懂的
binary program (可執行檔)
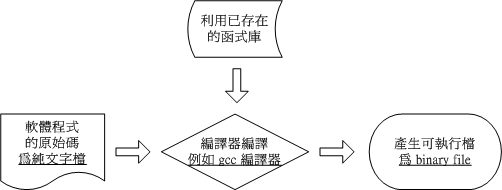
但其實用類似 gcc 的編譯器來進行編譯過程並不簡單
況且一套軟體並不會僅有一支程式, 而是包含一堆程式碼檔案。
所以除了每個主程式與副程式均需要寫上一筆編譯過程的指令外
還需要寫上最終的連結程序
當我們執行 make 時,
make 會在當時的目錄下搜尋 Makefile (or makefile) 這個文字檔
而 Makefile 裡面則記錄了原始碼如何編譯的詳細資訊
make 會自動的判別原始碼是否經過變動了,而自動更新執行檔
一般軟體開發商都會寫一支偵測程式來偵測
1.使用者的作業環境
2.該作業環境是否有軟體開發商所需要的其他功能
當偵測完畢後
就會主動建立 Makefile 的規則檔案
(一般常見偵測程式的檔案名為 configure 或者是 config !!!)
偵測作業環境目的在於判斷
(1)是否有適宜的編譯器可編譯該軟體的程式碼
(2)是否已存有該軟體所需之函式庫 or 其他所需的相依軟體
(3)作業系統平台是否和此軟體有適應,包括 Linux 的核心版本
(4)核心的表頭定義檔 (header include) 是否存在 (驅動程式必須要的偵測)

PyAudio
http://people.csail.mit.edu/hubert/pyaudio/

PortAudio主要是跨平台(Windows 、Unix、OS X) 的控制音檔 I/O 的 OpenSource
可以協助我們後續做Speech-Recognition Module
(支援 CPP、 python等程式語言)
PyAudio 則是 和他有相關的 Python 套件
可以用它去驅使Python 做 語音錄製後的STT後續功能
記得需要用到外接 麥克風音訊裝置(USB音效卡一個)
PyAudio 安裝指令
sudo apt-get install python-pyaudio python3-pyaudio

PortAudio 下載安裝
在你下載好 portaudio 的壓縮檔案後
可先行解壓縮
並切至該檔案夾目錄下
執行編譯的指令
cd portaudio
./configure
make
緊接著
第三階段. 使用密技
SpeechRecognition套件模組的下載
(使用到Google的語音)
這個套件庫支持 Google Speech Recognition
還有 Wit.ai 、AT&T跟 IBM 等公司的音訊資料協助程式設計師可做
語音轉文字功能
pip 指令
pip install SpeechRecognition

然後我遇到了滿江紅 嗚嗚嗚 T T
好想哭 好啦別怕
莫急~
莫荒~
莫害怕~
前面加上 sudo 然後 try again
就可以了喔
第四階段.撰寫python程式驅動錄音
之後就是寫程式的時間
1 2 3 4 5 6 7 8 | import speech_recognition as sr r = sr.Recognizer() with sr.Microphone() as source: print("Say something!") audio = r.listen(source) with open("recording.wav", "wb") as f: f.write(audio.get_wav_data()) |
寫完程式運行測試後的結果就是
兩種Error
第一階段的Error測試顯示出
Traceback (most recent call last):
File "speechRecog_Ex1.py", line 1, in <module>
import speech_recognition as sr
ImportError: No module named 'speech_recognition'
這邊透過 alias指令 切換 python目前使用版本
再重新下載 SpeechRecognition 的套件
重新執行

第二階段. Error訊息
Traceback (most recent call last):
File "speechRecog_Ex1.py", line 3, in <module>
with sr.Microphone() as source:
File "/usr/local/lib/python3.4/dist-packages/speech_recognition/__init__.py", line 78, in __init__
self.pyaudio_module = self.get_pyaudio()
File "/usr/local/lib/python3.4/dist-packages/speech_recognition/__init__.py", line 112, in get_pyaudio
raise AttributeError("PyAudio 0.2.9 or later is required (found version {})".format(pyaudio.__version__))
AttributeError: PyAudio 0.2.9 or later is required (found version 0.2.8)
我們剛剛安裝的 PyAudio 版本預設指令安裝到舊版

國外有程式設計師遭遇相同問題並在論壇發問
https://www.raspberrypi.org/forums/viewtopic.php?f=32&t=151200
這裡參考 國外老手的建議
有人說到由於 在Raspberry Pi 的Debian作業系統
目前0.2.8對於此版本系統是最新版本
所以無法靠指令直接快速升級
因此需要手動自行再下載0.2.9官方更新版本
重新編譯才行
不過有老鳥建議這個和我一樣遇到此棘手問題的發問者
先嘗試下看看 三個指令
當然能靠指令完事的是最好的問題解決方案
Keep It Simple, Stupid
Step1.Install portaudio19-dev
sudo apt-get install portaudio19-dev
Step2.Then install PyAudio with pip
sudo pip3 install PyAudio
Step3.If pip for python3 is not installed then install it too
sudo apt-get install python3-pip
試完之後果然一點用也沒有
還是無法運行 依然顯示0.2.9錯誤訊息
可是 !!!
有人說他下了這個指令之後
sudo pip3 install PyAudio
有顯示如下資訊
pi@raspberrypi:~/src $ sudo pip3 install PyAudio
Downloading/unpacking PyAudio
Downloading PyAudio-0.2.9.tar.gz (289kB): 289kB downloaded
Running setup.py (path:/tmp/pip-build-j2mfdfnj/PyAudio/setup.py) egg_info for package PyAudio
這裡想到一個方式
就是系統更新指令 !!!!
sudo apt-get update
sudo apt-get upgrade
sudo reboot
解決問題的思路
先更新目前作業系統
之後再嘗試剛才有人試成功的指令
嘗試後的結果仍然無法修正版本錯誤
不會自動更新抓新版本的 PyAudio
後來參考此link
https://pypi.python.org/pypi/SpeechRecognition/3.4.3
和非常重要的 pip 升級指令
How can I upgrade specific packages using pip and a requirements file?
https://stackoverflow.com/questions/4536103/how-can-i-upgrade-specific-packages-using-pip-and-a-requirements-file
終於成功修正 PyAudio版本更新問題
指令
sudo pip install pyaudio --upgrade
若有人還是無法
像我第二次在哏市話後重新安裝的系統環境嘗試
此紀錄之方法又有問題
可以試試看另一種方式
修改pip源頭
預設的source為pypi.python.org
修改pip source可以加速模塊的下載,可以大幅提高安裝效率
$ cd
$ mkdir .pip
$ cd .pip
$ vim pip.conf
輸入如下內容保存後退出:
[global] index-url = http://mirrors.aliyun.com/pypi/simple/ [install] trusted-host = mirrors.aliyun.com
重新執行點下載命令
sudo apt purge python3-pyaudio
sudo apt install portaudio19-dev python-all-dev
sudo pip3 install pyaudio==0.2.9 --upgrade
ref link:
https://askubuntu.com/questions/915227/how-do-i-get-pyaudio-0-2-9-installed-on-ubuntu-16-04
https://lizonghang.github.io/2016/07/30/Python%E5%AE%9E%E7%8E%B0%E5%BD%95%E9%9F%B3%E5%8A%9F%E8%83%BD/
若要查看安裝了哪些 pip 套件
指令
pip list


目前最新版已經到 pyAudio 0.2.11
成功執行程式後
我們於終端機Run程式
測試
這次又有新的錯誤是有關於 ALSA的設定問題
Error如下圖顯示


Ref:
ImportError: No module named SpeechRecognition
https://stackoverflow.com/questions/43806542/importerror-no-module-named-speechrecognition
Trouble Getting PyAudio 0.2.9
https://www.raspberrypi.org/forums/viewtopic.php?f=32&t=151200
Error for Pyaudio 0.2.9 version
https://github.com/Uberi/speech_recognition/issues/104
How install pyaudio 0.2.9
https://www.codeproject.com/Questions/1130087/How-install-pyaudio
How can I upgrade specific packages using pip and a requirements file?
PortAudio on Raspberry Pi
https://app.assembla.com/wiki/show/portaudio/Platforms_RaspberryPi
Speech Recognition using Google Speech API
https://pythonspot.com/en/speech-recognition-using-google-speech-api/
蓝林鸟的博客 - Portaudio的安装与语音信号采集
http://www.ramlinbird.com/portaudio%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E8%AF%AD%E9%9F%B3%E4%BF%A1%E5%8F%B7%E9%87%87%E9%9B%86/
师母已呆-2015的博客
http://blog.sina.com.cn/s/blog_13d4ad50b0102v7rz.html
PortAudio编程入门 V19
https://my.oschina.net/sulliy/blog/77055
coding portaudio-wavplay-demo.cpp (screen recording)
https://www.youtube.com/watch?v=7f1U6jG3RAw



留言
張貼留言