T-SQL筆記27_資料庫定序_中文where條件過濾查不出來
SELECT DATABASEPROPERTYEX ('DB名稱' ,'Collation' )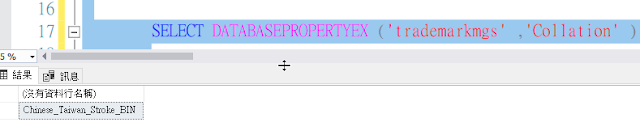
| 定序 | 描述 |
|---|---|
Chinese_PRC_CI_AS | Chinese-PRC、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Chinese_Taiwan_Stroke_CI_AS | Chinese-Taiwan-Stroke、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Finnish_Swedish_CI_AS | 芬蘭文、瑞典文和瑞典文 (芬蘭)、不區分大小寫、區分重音、卡納型不區分、不區分假名 |
French_CI_AS | 法文、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Hebrew_BIN | 希伯來文、二進位排序 |
Hebrew_CI_AS | 希伯來文、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Japanese_BIN | 日文、二進位排序 |
Japanese_CI_AS | 日文、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Japanese_CS_AS | 日文、區分大小寫、區分重音、不區分假名、不區分寬度 |
Korean_Wansung_CI_AS | Korean-Wansung、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Latin1_General_100_BIN | Latin1-General-100、二進位排序 |
Latin1_General_100_BIN2 | Latin1-General-100、二進位代碼點比較排序 |
Latin1_General_100_CI_AS | Latin1-General-100、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Latin1_General_BIN | Latin1-General、二進位排序 |
Latin1_General_BIN2 | Latin1-General、二進位代碼點比較排序 |
Latin1_General_CI_AI | Latin1-General、不區分大小寫、不區分重音、不區分假名、不區分寬度 |
Latin1_General_CI_AS | Latin1-General、不區分大小寫、區分重音、不區分假名、不區分寬度 |
Latin1_General_CI_AS_KS | Latin1-General、不區分大小寫、區分重音、區分假名、不區分寬度 |
Latin1_General_CS_AS | Latin1-General、區分大小寫、區分重音、不區分假名、不區分寬度 |
Modern_Spanish_CI_AS | Modern-Spanish、不區分大小寫、區分重音、不區分假名、不區分寬度 |
SQL_1xCompat_CP850_CI_AS | Latin1-General、不區分大小寫、區分重音、不區分假名、不區分寬度,適用於非 Unicode 資料字碼頁 850 上的 Unicode 資料、SQL Server 排序 49 |
SQL_Latin1_General_CP1_CI_AI | Latin1-General、不區分大小寫、不區分重音、不區分假名、不區分寬度,適用於非 Unicode 資料字碼頁 1252 上的 Unicode 資料、SQL Server 排序 54 |
SQL_Latin1_General_CP1_CI_AS (預設值) | Latin1-General、不區分大小寫、區分重音、不區分假名、不區分寬度,適用於非 Unicode 資料字碼頁 1252 上的 Unicode 資料、SQL Server 排序 52 |
SQL_Latin1_General_CP1_CS_AS | Latin1-General、不區分大小寫、區分重音、不區分假名、不區分寬度,適用於非 Unicode 資料字碼頁 1252 上的 Unicode 資料、SQL Server 排序 51 |
SQL_Latin1_General_CP437_CI_AI | Latin1-General、不區分大小寫、不區分重音、不區分假名、不區分寬度,適用於非 Unicode 資料字碼頁 437 上的 Unicode 資料、SQL Server 排序 34 |
SQL_Latin1_General_CP850_BIN2 | Latin1-General、二進位代碼點比較排序,適用於非 Unicode 資料字碼頁 850 上的 Unicode 資料、SQL Server 排序 40 |
SQL_Latin1_General_CP850_CI_AS | Latin1-General、不區分大小寫、區分重音、不區分假名、不區分寬度,適用於非 Unicode 資料字碼頁 850 上的 Unicode 資料、SQL Server 排序 42 |
SQL_Latin1_General_CP1256_CI_AS | Latin1-General、不區分大小寫、區分重音、不區分假名、不區分寬度,適用於非 Unicode 資料字碼頁 1256 上的 Unicode 資料、SQL Server 排序 146 |



留言
張貼留言