透過單方向LSTM進行短時間的交通流量預測_part1.資料預處理和EDA特徵挑選(使用PEMS04資料集)

這邊會用PEMS04資料集做交通流量預測的測試(以下提供3個資料集下載連結)
https://github.com/Davidham3/ASTGCN-2019-mxnet/blob/master/data/README.md
Each npz file contains one key, named "data", the shape is (sequence_length, num_of_vertices, num_of_features).
數據集來源於PeMS網站,包含了三藩市灣區(美國加尼福尼亞州三藩市大灣區)29條高速公路上的3848個探測器在2018年1月1日至2018年2月28日期間的數據。 這些探測器每5分鐘收集一次數據,記錄了3848個感測器每5分鐘經過的車輛數。
Performance Measurement System (PeMS) Data Source
地圖上顯示的交通數據是從 39,000 多個單獨的檢測器中即時收集的。這些感測器覆蓋加利福尼亞州所有主要大都市地區的高速公路系統。
在這篇文獻Problem: Road Trajectory Prediction 有介紹到該數據集維度

浙江大学学报(工学版)這篇文獻也可供參考

探測器節點數: 307
特徵數(每個探測器每次採集的數據有3個維度特徵): 3
數據時長: 59天
時間視窗: 5分鐘
可登入Kaggle後下載資料集
Processing traffic data for deep learning projects
https://www.kaggle.com/code/shlokkaushik/processing-traffic-data-for-deep-learning-projects/input

PeMS04 is a traffic forecasting benchmark.
被很多偏論文研究使用
https://paperswithcode.com/dataset/pems04

預設.npz副檔名沒辦法preview,它是必須用python numpy讀取才能打開。
是一個numpy獨有的壓縮檔。
這邊另一個則是csv可以先預覽有三個欄位。
(但npz跟csv各自資料涵義不同)

有三個欄位
from(原感測節點編號)
to(目的感測節點編號)
cost(耗費成本也就是相鄰距離)
這邊用到的是npz檔案,將數據下載解壓後放到專案指定相對目錄下。
npz會類似字典有key-value形式存儲的壓縮檔,因此可觀察有哪些key。
根據推算,每隔5分鐘採集一次數據,因此一小時內可以採集12次。一天有24小時,又採集了59天。因此數據總量:16992=59×24×12。
Phase1.這邊可以先用python載入資料,可驗證我們數據總量。
#coding:utf-8 import numpy as np import matplotlib.pyplot as plt flow_data = np.load("./data/PEMS04.npz") keys = [key for key in flow_data.keys()] print("Keys in the dataset:", keys) print("Number of keys in the dataset:", len(keys)) data = flow_data['data'] print("Shape of the data:", data.shape) print("First few data entries:", data[:5])
這個.npz文件通常包含多維數據陣列,這些數據陣列可能包含速度、流量、佔用率等資訊可運用。用切片技巧,取得data陣列中索引從0到4的元素(前五筆資料觀察)。
這邊有用的只有單一個key也就是data

data這個陣列包含的是三維數據。每一個內層的陣列看起來代表了一個時間點的交通數據。
車流量(在此時段內多少車輛通過)
平均車速
平均車道佔有率
在此篇論文文獻中可以查找到該資料集更正確的說明
The PEMS04 dataset consists of feature data in three dimensions: traffic flow, average speed, and average lane occupancy. It includes data from 307 nodes in the San Francisco Bay Area and spans from 1 January 2018 to 28 February 2018.

這邊調整打印不用科學記號表示(比較不直觀)
#coding:utf-8 import numpy as np import matplotlib.pyplot as plt # 設置列印選項,關閉科學記數法,precision控制小數點後的位數到第5位 np.set_printoptions(suppress=True, precision=5) flow_data = np.load("./data/PEMS04.npz") keys = [key for key in flow_data.keys()] print("Keys in the dataset:", keys) print("Number of keys in the dataset:", len(keys)) data = flow_data['data'] print("Shape of the data:", data.shape) print("First few data entries:", data[:5])

資料集numpu載入進來的dataframe第二個維度表示感測器編號共有307個


Phase2.可視化各特徵關聯趨勢並計算變異數統計指標
如果要查看特定感測器節點所有三個維度數據
比方
node_id:0
flow_data[:, 0, :]
node_id:1
flow_data[:, 1, :]
.....
node_id:306
flow_data[:, 306, :]
這邊抓node_id:1
來確認車流量比較有特徵選用價值
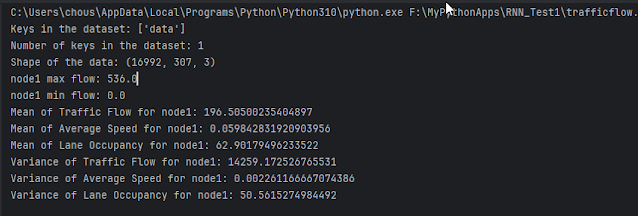
#coding:utf-8 import numpy as np import matplotlib.pyplot as plt # 設置列印選項,關閉科學記數法,precision控制小數點後的位數到第5位 np.set_printoptions(suppress=True, precision=5) flow_data = np.load("./data/PEMS04.npz") keys = [key for key in flow_data.keys()] print("Keys in the dataset:", keys) print("Number of keys in the dataset:", len(keys)) flow_data = flow_data['data'] print("Shape of the data:", flow_data.shape) #print("First few data entries:", data[:5]) # 設定中文字體 plt.rcParams['font.family'] = 'Microsoft JhengHei' plt.rcParams['axes.unicode_minus'] = False # 正確顯示負號 node_id = 1 plt.plot(flow_data[: 24 * 12, node_id, 0], label='車流量', color='blue') #plt.savefig("node_{:3d}_1.png".format(node_id)) plt.plot(flow_data[: 24 * 12, node_id, 1], label='平均車速', color='green') #plt.savefig("node_{:3d}_2.png".format(node_id)) plt.plot(flow_data[: 24 * 12, node_id, 2], label='平均車道佔有率', color='red') #plt.savefig("node_{:3d}_3.png".format(node_id)) plt.xlabel("Time (5-minute intervals)") plt.ylabel("Measurement") plt.title("Traffic Data Measurements for Node {}".format(node_id)) plt.legend()#要加才會顯示不同顏色曲線的涵義Label於右上角。 plt.show() #統計指標 max_flow = np.max(flow_data[:,node_id,0]) min_flow = np.min(flow_data[:,node_id,0]) print("node1 max flow:", max_flow) print("node1 min flow:", min_flow) mean_traffic_flow = np.mean(flow_data[:,node_id,0]) mean_average_speed = np.mean(flow_data[:,node_id,1]) mean_lane_occupancy = np.mean(flow_data[:,node_id,2]) print("Mean of Traffic Flow for node1:", mean_traffic_flow) print("Mean of Average Speed for node1:", mean_average_speed) print("Mean of Lane Occupancy for node1:", mean_lane_occupancy) # Calculate variances var_traffic_flow = np.var(flow_data[:, node_id, 0]) var_average_speed = np.var(flow_data[:, node_id, 1]) var_lane_occupancy = np.var(flow_data[:, node_id, 2]) print("Variance of Traffic Flow for node1:", var_traffic_flow) print("Variance of Average Speed for node1:", var_average_speed) print("Variance of Lane Occupancy for node1:", var_lane_occupancy)
透過特徵選取手法:
刪除不具備參考利用價值的特徵(比方變異數過低)
白話來說就是特定維度特徵資料每個點都差不多,沒有很顯著的落差變化。
其他可以捨棄
Phase3.特徵擷取與預處理(正規化車流量)
80%做訓練集,剩下20%做測試集
使用滑動窗口方法從訓練序列和測試序列中進一步提取數據
13個時刻劃分為一個樣本
#coding:utf-8 import numpy as np import matplotlib.pyplot as plt # 設置列印選項,關閉科學記數法,precision控制小數點後的位數到第5位 np.set_printoptions(suppress=True, precision=5) # 設定中文字體 plt.rcParams['font.family'] = 'Microsoft JhengHei' plt.rcParams['axes.unicode_minus'] = False # 正確顯示負號 node_id = 1 #加載raw_data並獲取車流量,將資料縮放到特定範圍內。 def get_flow(file_name,node_id): flow_data = np.load(file_name) flow_data = flow_data['data'][:,node_id,0] dmin,dmax = flow_data.min(), flow_data.max() flow_data = (flow_data-dmin)/(dmax-dmin) #正規化(將數據線性轉換到0和1之間。) return flow_data #透過滑動窗口方式抓數據集做拆分。 def sliding_window(seq , window_size): result = [] for i in range(len(seq) - window_size): result.append(seq[i:i+window_size]) return result traffic_data = get_flow("./data/PEMS04.npz",node_id) print(traffic_data.shape) data = traffic_data.copy() sensordata_num = len(data) print(sensordata_num) train_set, test_set = [], [] train_seq = data[:int(sensordata_num * 0.8)] #80%做訓練集,剩下20%做測試集 test_seq = data[int(sensordata_num * 0.8):] #使用滑動窗口方法從訓練序列和測試序列中進一步提取數據,窗口大小設為13。 #13個時刻劃分為一個樣本 train_set += sliding_window(train_seq, window_size=13) test_set += sliding_window(test_seq, window_size=13) train_set, test_set = np.array(train_set).squeeze(), np.array(test_set).squeeze() print(train_set.shape, test_set.shape) print(train_set, test_set) #從滑動窗口生成的數據集中提取特徵(前12個點)和標籤(最後一個點)。 X_train = train_set[:, :12] y_train = train_set[:, -1] X_test = test_set[:, :12] y_test = test_set[:, -1] X_train = np.expand_dims(X_train, axis=-1) #提升維度 X_test = np.expand_dims(X_test, axis=-1)#提升維度 print(X_train.shape, X_test.shape)

打印train_set,test_set各自shape
(13580, 13) (3386, 13)
Ref:
Traffic Prediction on PeMS04
https://paperswithcode.com/sota/traffic-prediction-on-pems04
https://paperswithcode.com/dataset/pems04
https://onlinelibrary.wiley.com/doi/pdf/10.1155/2023/7099652
交通數據集PEMS04介紹
https://blog.csdn.net/gitblog_09724/article/details/143005863
Deep Learning on Traffic Prediction: Methods, Analysis and Future Directions
Traffic Forecasting with Graph Convolutional Network and Gated Recurrent Unit using Internal
and External Factors in Different Domains
https://www.cnblogs.com/emanlee/p/17923764.html
https://academax.com/ZDXBGXB/doi/10.3785/j.issn.1008-973X.2023.08.007
給自己的Python小筆記 - Numpy如何讀寫檔案? - NumPy獨有的npy和npz二進制檔案格式和text(.txt)檔案格式 - 讀取/寫入教學
https://matters.town/a/k50fv7lzpioq
https://blog.csdn.net/qq_43391414/article/details/118573169
Python中如何读取npy、npz文件?
https://www.cnblogs.com/xzit201802/p/17158304.html
其他延伸類似資料集應用
ECML/PKDD 15: Taxi Trip Time Prediction (II)
https://www.kaggle.com/c/pkdd-15-taxi-trip-time-prediction-ii
RTA Freeway Travel Time Prediction
https://www.kaggle.com/competitions/RTA/data



留言
張貼留言