Hadoop 生態系統當中的Flume,Sqoop ,Pig,Hive
Hadoop 生態系統由支持彼此進行大數據處理的組件組成。
我們可以根據各種階段檢查 Hadoop 生態系統。

當從多個來源接收數據時,Flume 和 Sqoop 負責攝取數據並將它們傳輸到存儲組件 HDFS 和 HBase。
然後,數據被分配到像 Pig 和 Hive 這樣的 MapReduce 框架來處理和分析數據,並通過並行計算來完成處理。


Sqoop (SQL to Hadoop)
- Sqoop 於 2012 年 3 月正式從孵化專案畢業,成為 Apache 的頂級專案。
- Apache Sqoop 是一個專為在 Hadoop 和結構化資料存儲(例如關聯式資料庫)之間高效傳輸大量資料而設計的工具。
- Sqoop 允許使用者從關聯式資料庫(RDBMS)中擷取資料到 Hadoop,供後續分析使用。
- Sqoop 也能將分析結果匯入資料庫,供其他用戶端程式使用。
- 它使用 JDBC 來存取關聯系統。
- Sqoop 存取資料庫以了解要傳輸的資料結構,並生成一個 MapReduce 應用程式來匯入或匯出資料。
- 當使用 Sqoop 將資料匯入 Hadoop 時,Sqoop 會生成一個 Java 類別來封裝匯入表中的每一row。
- Sqoop 匯入命令用於從關聯式資料表提取資料並載入到 Hadoop 中。
- HDFS 中的每一筆資料於資料表中的每一row。
- 匯入到 HDFS 的資料可以存為文字檔案、二進位檔案,或直接匯入到 HBase 或 Hive。
- 預設情況下,會匯入all rows of a table,但可透過參數指定特定的columns或使用 WHERE 子句限制匯入的rows。甚至可以自行定義查詢來存取關聯式資料。
- 若需指定匯入資料的存放位置,可以使用 --target-dir 參數。否則,目標目錄名稱將與資料表名稱相同。
- 欄位與記錄格式預設使用逗號分隔欄位,每條記錄以換行符號結束。匯入與匯出指令都可以覆寫此行為。
Sqoop 提供命令列介面來傳輸資料,支援以下功能:
- 從單一資料庫表或free-form SQL 查詢進行增量載入(incremental loads)。
- 使用腳本,在需要時匯入自上次匯入以來對資料庫的更新。
- 將資料載入 Hive 或 HBase 的資料表中。(populate tables in Hive or HBase)
無論是匯入還是匯出,連線資訊都是相同的。需要指定 JDBC 連接字串、使用者名稱和密碼。例如,若要連接到一個port為 50000 的 DB2 系統,主機名稱為 your.db2.com,使用者 ID 為 db2user,密碼為 db2password,可以使用下列語法:

Sqoop 匯入(Import)
Sqoop 匯入(Import)語句,該語句會從 DB2 資料庫 yourDB 中的資料表 db2table 提取所有橫列與所有欄位。匯入結果將儲存在 HDFS 的目錄 sqoopdata 中:sqoop import --connect jdbc:db2://your.db2.com:50000/yourDB \
--username db2user --password db2password \
--table db2table --target-dir sqoopdata

- Sqoop 以平行模式匯入資料(imports the data in parallel),預設使用 4 個 Mapper。可以自訂 Mapper 的數量。
- Sqoop 預設使用資料表的主鍵(Primary Key)來分割資料,並確定主鍵的最小值和最大值。假設數值均勻分佈。如果需要更改分割的欄位,可以使用 --split-by 參數。
- 若資料表無索引欄位或有多欄鍵(Multi-column Key),則必須指定 --split-by 欄位參數
- 若只需匯入部分欄位,可使用 --columns 參數,並以逗號分隔欄位名稱。
- 若只需匯入部分橫列資料,可使用 --where 參數,指定一個 SQL 條件來限制行數,甚至可以透過多表聯結查詢資料。
- 匯入的資料預設為分隔文字格式(--as-textfile)。您也可以選擇匯入為以下格式:
二進位格式:--as-sequencefile
Avro 資料格式:--as-avrodatafile - 此外,您可以啟用資料壓縮功能,覆寫預設行為。
Sqoop 匯出(Export)
- Sqoop 匯出將 Hadoop 中的資料匯出到關聯式資料表。
- 目標資料表必須已存在,並且可以指定自己的解析規範。
- 預設模式為插入模式(Insert Mode),用於將資料插入新資料表。若插入過程中出現錯誤,匯出會失敗。
- 更新模式(Update Mode):會產生 UPDATE 語句。要使用此模式,必須指定 --update-key 參數,告知 Sqoop 在 WHERE 子句中使用哪些欄位(可用逗號分隔多個欄位)。如果更新語句未修改任何行,不會視為錯誤。
- UPSERT 模式(Update or Insert):部分資料庫支援此模式,會嘗試更新已存在的行,若不存在則插入新行。
- 呼叫模式(Call Mode):會調用存儲過程(Stored Procedure)並將記錄傳遞給它。
--export-dir 參數定義要從 HDFS 匯出的檔案位置。例如:
1.匯出 /employeedata/processed 目錄中的資料到資料表 employee:
sqoop export --connect jdbc:db2://your.db2.com:50000/yourDB \
--username db2user --password db2password \
--table employee --export-dir /employeedata/processed
2.調呼叫存儲過程:
sqoop export --connect jdbc:db2://your.db2.com:50000/yourDB \
--username db2user --password db2password \
--call my_stored_procedure --export-dir /employeedata/processed
3.使用 empno 欄位更新資料表
sqoop export --connect jdbc:db2://your.db2.com:50000/yourDB \
--username db2user --password db2password \
--table employee --export-dir /employeedata/processed \
--update-key empno
交易處理(Transactions):
- Sqoop 在執行插入時,使用多row插入,每次最多插入 100 row。
- Mapper 每執行 10,000 row插入後提交(Commit)一次。
- 每個 Mapper 都以單獨的交易進行提交。

- 是 Hadoop 生態系統的一部分,由 Cloudera 開發。
- 最初,它被設計為僅處理日誌數據,但後來,它被開發為處理事件數據。
- 主要用於將大量基於事件的資料(尤其是非結構化資料)攝取到 Hadoop 中。
- Flume 將這些檔案移至 Hadoop 分散式檔案系統 (HDFS) 進行進一步處理,並且可以靈活地寫入 HBase 或 Solr 等其他儲存解決方案。因此,Apache Flume 是一個優秀的資料擷取工具,適合使用 Hadoop 聚合、儲存和分析資料。

Hive
Hive 架構的三個主要部分是 Hive Client、Hive Services以及 Hive Storage & Computing。
(1)Hive Client
提供不同的驅動程序以便根據應用類型進行通訊。例如,對於 Java-based的應用,它使用 JDBC 驅動程序,其他類型的應用將使用 ODBC 驅動程序。
(2)Hive Services
客戶互動通過 Hive 服務完成。 任何查詢操作都在這裡完成,像是BeeLine這類命令行界面充當 Hive 服務的界面。
Hive 服務器(HiveServer)用於運行查詢並允許多個客戶提交請求。 它旨在支持 JDBC 和 ODBC 客戶端。
驅動程序(Driver)接收通過命令行提交的查詢語句,並在啟動會話後將查詢發送給編譯器(Compiler)。
優化器(Optimizer)對執行計劃進行變換並拆分任務,以幫助提速和提高效率。
執行器在優化器拆分任務後執行任務。元存儲(metastore)是用於存儲元數據的存儲,是關於表的信息。元存儲負責將這些信息保持在一個中央位置。
(3)Hive Storage & Computing
客戶端依次與 Hive 存儲和計算通訊,以執行以下操作:
把表的元數據信息存儲在某種數據庫中。
查詢結果和表中加載的數據存儲在 Hadoop 集群或 HDFS 中。
- 是建構於 Hadoop 之上的資料倉儲框架(a framework for data warehousing),旨在讀取、寫入和管理大型表格型數據集和數據分析。
- 資料倉庫儲存來自多個不同來源的歷史數據,以便您可以分析並從中提取洞見。 這些洞見用於報告。
- Hive 查詢語言(稱 Hive QL)是根據 SQL 去設計的。
- 是寫給精熟SQL技能但缺乏Java 程式設計技能的分析師們,用於查詢存於 HDFS 的海量資料。眾所周知,SQL擁有廣為業界熟知的龐大優勢,是商業智慧(business intelligence)的通用語法(lingua franca,就像 ODBC 是通用橋接器一樣),因此 Hive 能與這些商品做緊密的整合。
- Hive 支持以下文件格式:二進位鍵值對的序列文件、儲存表格中列的列式數據庫的記錄列式文件,以及文本或平面文件。
- Hive 允許根據用戶的需求進行數據清理和過濾任務。
- Hive 適用於靜態數據分析。別於傳統 RDBMS 允許用戶進行多次讀寫操作,Hive 基於一次寫入,多次讀取的方法。
- 別於傳統 RDBMS 可處理高達 terabytes 的數據。Hive設計用於處理高達petabytes 的數據。
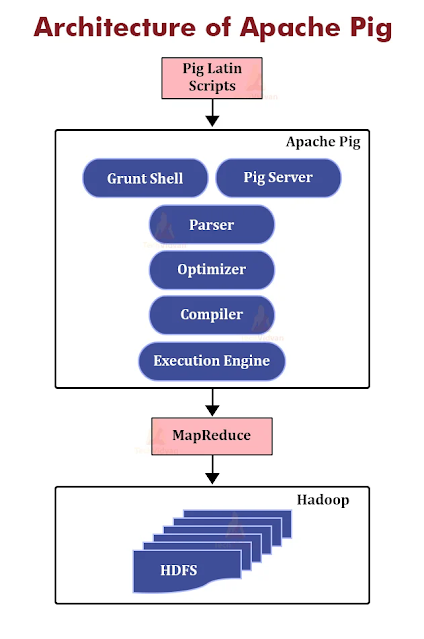
Pig
- 是一種高階腳本語言,用於基於查詢的資料服務處理。
- Apache Pig可以提取數據,對其執行操作,並將數據以所需的格式轉儲回HDFS。可以將它用於 ETL操作。
- Pig有兩個主要元件,分別是Pig Latin語言和Pig運行時環境。在 Pig 運行時環境中,執行 Pig Latin 程式。熟悉腳本語言和 SQL 的開發人員可以利用 Pig Latin。這為開發人員提供了使用 Pig 進行程式設計的便利性。
- 在 Apache Pig 開發之前,編寫 MapReduce 任務是處理 HDFS 中資料的唯一方法。
- 其主要目標是在 Hadoop 中執行更大資料集的查詢,並以所需的格式進一步組織最終輸出。
2006 年,Pig 被開發為雅虎的研究項目,特別是用於在每個資料集上建立和執行 MapReduce 作業。
2007 年,Pig 透過 Apache 孵化器開源。
2008年,Apache Pig的第一個版本問世。
2010年,Apache Pig成為Apache頂級專案。

Q1.Which statement is true regarding the comparison between traditional RDBMS and Apache Hive?
Traditional RDBMS is used to maintain a data warehouse. Hive is used to maintain a database and uses the structured query language known as SQL.
(O)Traditional RDBMS can handle up to terabytes of data. Hive is designed to handle petabytes of data.
Traditional RDBMS is based on the write once, read many methodologies. Hive allows for as many read operations and write operations as a user needs.
Traditional RDBMS always have built-in support for data partitioning, whereas Hive does not support partitioning.
解析:
Hive can handle petabytes of data in the place of terabytes handled by traditional RDBMS.



留言
張貼留言