設置單節點Hadoop

運行以下命令,將hadoop-3.3.6.tar.gz下載到您的 theia 環境。
curl https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz --output hadoop-3.3.6.tar.gz
解壓當前目錄中的 tar 檔。
tar -xvf hadoop-3.3.6.tar.gz
檢查hadoop命令,看看它是否已設置。這將顯示hadoop腳本的使用文檔。
bin/hadoop

curl https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0225EN-SkillsNetwork/labs/data/data.txt --output data.txt

運行 Map reduce 應用程式以對 data.txt 進行字數統計並將輸出儲存到/user/root/output
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount data.txt output

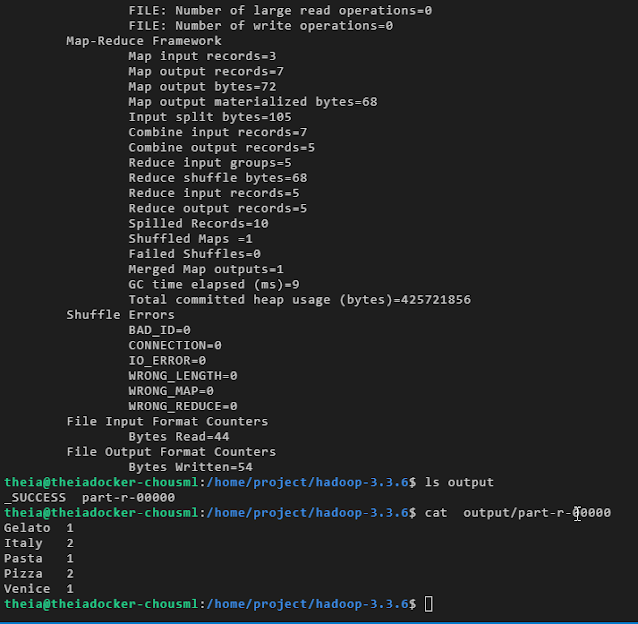
一旦字數計算成功,您可以運行以下命令來查看它生成的輸出文件。
應該會看到 part-r-00000 和 _SUCCESS,表示單詞計數已完成。
運行cat命令以查看字數輸出。
ls output
cat output/part-r-00000

若要重新跑程式就先將data.txt與output目錄分別依序刪除
rm data.txt
rm -rf output


nano data.txt
Italy Venice
Italy Pizza
Pizza Pasta Gelato

bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount data.txt output



留言
張貼留言