Spark 中的常見窄/寬轉換和Rule-Based/Cost-Based優化技術_窄轉換(narrow transformations)和寬轉換(wide transformations)



窄轉換(narrow transformations)
將各種類型的數據放在單獨的容器中。可以對每個數據容器執行操作,也可以在容器之間獨立行動數據,而無需交互或傳輸。窄轉換的範例包括修改單個數據片段、選擇特定項或組合兩個數據容器。
- 在窄轉換中,無需執行數據隨機排序操作即可傳輸數據。
- 當父 RDD 的每個分區最多被子 RDD 的一個分區使用時,我們的依賴關係很窄。
一對一映射:子 RDD 中的每個分區最多依賴於父 RDD 中的一個分區。換言之,子分區僅處理來自單個相應父分區的數據。 - 更快的執行速度:窄依賴項支援流水線等優化。在流水線中,一個轉換的輸出可以用作下一個轉換的輸入,而無需等待處理整個父 RDD。這提高了效率。
- 減少隨機排序:由於每個子分區都有一個特定的父分區可供訪問,因此無需通過網路對數據進行隨機排序。
- 例如: map 、 filter 和 union 轉換
備註:隨機排序是指數據在Spark集群中的不同 worker節點之間移動。
窄轉換常見例子
Map: Applying a function to each element in the data set.
from pyspark import SparkContext sc = SparkContext("local", "MapExample") data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) mapped_rdd = rdd.map(lambda x: x * 2) mapped_rdd.collect() # Output: [2, 4, 6, 8, 10]
Filter: Selecting elements based on a specified condition.
from pyspark import SparkContext sc = SparkContext("local", "FilterExample") data = [1, 2, 3, 4, 5] rdd = sc.parallelize(data) filtered_rdd = rdd.filter(lambda x: x % 2 == 0) filtered_rdd.collect() # Output: [2, 4]
Union: Combining two data sets with the same schema.
from pyspark import SparkContext sc = SparkContext("local", "UnionExample") rdd1 = sc.parallelize([1, 2, 3]) rdd2 = sc.parallelize([4, 5, 6]) union_rdd = rdd1.union(rdd2) union_rdd.collect() # Output: [1, 2, 3, 4, 5, 6]
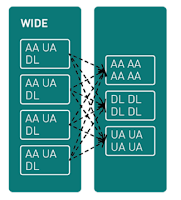

寬轉換(wide transformations)
寬轉換類似於在不同組之間重新排列和重新分配數據。想像一下,您想要以新的方式組合或組織數據集。但是,此任務並不像僅使用一個數據集那樣簡單。您需要在這些數據集之間協調和行動數據,這涉及更複雜的數據。例如,根據通用屬性合併兩個數據集需要在它們之間重新排列數據,這使其成為數據工程中的一種廣泛轉換。
- 寬轉換涉及跨分區對數據進行隨機排序。
- 當父 RDD 的每個分區可能被多個子分區依賴(廣泛依賴)時,計算速度可能會受到顯著影響,因為我們在創建新分區時可能需要在不同節點周圍隨機排列數據。
多對一映射:子 RDD 中的每個分區可能需要來自父 RDD 的多個分區的數據。這需要跨網路對數據進行隨機排序,以將所需的數據整合在一起。 - 執行速度較慢:廣泛的依賴項通常涉及隨機排序,這可能是一個瓶頸。通過網路對數據進行隨機排序需要時間和資源,從而影響Spark應用程式的整體性能。
- 複雜性增加:廣泛的依賴項會使優化 Spark 作業更具挑戰性。流水線效率會降低,因為轉換可能需要等待隨機數據後再繼續。
寬轉換常見例子
GroupBy: Aggregating data based on a specific key.
from pyspark import SparkContext sc = SparkContext("local", "GroupByExample") data = [("apple", 2), ("banana", 3), ("apple", 5), ("banana", 1)] rdd = sc.parallelize(data) grouped_rdd = rdd.groupBy(lambda x: x[0]) sum_rdd = grouped_rdd.mapValues(lambda values: sum([v[1] for v in values])) sum_rdd.collect() # Output: [('apple', 7), ('banana', 4)]
Join: Combining two data sets based on a common key.
from pyspark import SparkContext sc = SparkContext("local", "JoinExample") rdd1 = sc.parallelize([("apple", 2), ("banana", 3)]) rdd2 = sc.parallelize([("apple", 5), ("banana", 1)]) joined_rdd = rdd1.join(rdd2) joined_rdd.collect() # Output: [('apple', (2, 5)), ('banana', (3, 1))]
Sort: Rearranging data based on a specific criterion.
from pyspark import SparkContext sc = SparkContext("local", "SortExample") data = [4, 2, 1, 3, 5] rdd = sc.parallelize(data) sorted_rdd = rdd.sortBy(lambda x: x, ascending=True) sorted_rdd.collect() # Output: [1, 2, 3, 4, 5]
PySpark DataFrame(Rule-based common transformations)
1.Predicate pushdown(謂詞下推):
Pushing filtering conditions closer to the data source before processing to minimize data movement.
在處理之前,將篩選條件推得更靠近數據源,以最大程度地減少數據移動。
2.Constant folding(恆定摺疊):
Evaluating constant expressions during query compilation to reduce computation during runtime.
在查詢編譯期間計算常量表達式,以減少運行時的計算。
3.Column pruning(欄位修剪):
Eliminating unnecessary columns from the query plan to enhance processing efficiency.
從查詢計劃中去除不必要的欄位,以提高處理效率。
4.Join reordering(Join 重新排序):
Rearranging join operations to minimize the intermediate data size and enhance the join performance.
重新排列join操作以最小化中間數據大小並提高join性能。
簡易示範上述四種Rule-based優化技法
from pyspark.sql import SparkSession from pyspark.sql.functions import col # Create a Spark session spark = SparkSession.builder.appName("RuleBasedTransformations").getOrCreate() # Sample input data for DataFrame 1 data1 = [ ("Alice", 25, "F"), ("Bob", 30, "M"), ("Charlie", 22, "M"), ("Diana", 28, "F") ] # Sample input data for DataFrame 2 data2 = [ ("Alice", "New York"), ("Bob", "San Francisco"), ("Charlie", "Los Angeles"), ("Eve", "Chicago") ] # Create DataFrames columns1 = ["name", "age", "gender"] df1 = spark.createDataFrame(data1, columns1) columns2 = ["name", "city"] df2 = spark.createDataFrame(data2, columns2) # Applying Predicate Pushdown (Filtering) filtered_df = df1.filter(col("age") > 25) # Applying Constant Folding folded_df = filtered_df.select(col("name"), col("age") + 2) # Applying Column Pruning pruned_df = folded_df.select(col("name")) # Join Reordering reordered_join = df1.join(df2, on="name") # Show the final results print("Filtered DataFrame:") filtered_df.show() print("Folded DataFrame:") folded_df.show() print("Pruned DataFrame:") pruned_df.show() print("Reordered Join DataFrame:") reordered_join.show() # Stop the Spark session spark.stop()
Predicate pushdown的實踐
對 DataFrame “df1” 應用篩選器,以僅選擇 “age” 列大於 25 的資料列。
Constant folding的實踐
對 folded_df 中的 「age」 列執行算術運算,添加常量值 2
Column pruning的實踐
僅選擇pruned_df中的 「name」 欄位,從而從查詢計畫中消除不必要的欄位。
Join reordering的實踐
在 「name」欄位上執行 df1 和 df2 之間的聯接,使 Spark 能夠對聯接進行重新排序以獲得更好的性能。
Cost-Based optimization techniques in Spark
Spark 採用根據成本的優化技術來提高查詢執行的效率。
這些方法涉及估算和分析與查詢相關的成本。
1.Adaptive query execution(自適應查詢執行):
Dynamically adjusts the query plan during execution based on runtime statistics to optimize performance.
在執行期間根據運行時統計資訊動態調整查詢計劃以優化性能。
2.Cost-based join reordering(基於成本的聯接重新排序):
Optimizes join order based on estimated costs of different join paths.
根據不同連接路徑的估計成本優化連接順序。
3.Broadcast hash join(廣播Hash 聯接):
Optimizes small-table joins by broadcasting one table to all nodes, reducing data shuffling.
通過將一個表廣播到所有節點來優化小表聯接,從而減少數據隨機排序。
4.Shuffle partitioning and memory management(Shuffle 分區和記憶體管理):
Efficiently manages data shuffling during operations like groupBy and aggregation and optimizes memory usage.
高效管理 groupBy 和 aggregation 等操作期間的數據 shuffle,並優化記憶體使用。
簡易示範Cost-based優化技法中Enable adaptive query execution
from pyspark.sql import SparkSession from pyspark.sql.functions import col # Create a Spark session spark = SparkSession.builder.appName("CostBasedOptimization").getOrCreate() # Sample input data for DataFrame 1 data1 = [ ("Alice", 25), ("Bob", 30), ("Charlie", 22), ("Diana", 28) ] # Sample input data for DataFrame 2 data2 = [ ("Alice", "New York"), ("Bob", "San Francisco"), ("Charlie", "Los Angeles"), ("Eve", "Chicago") ] # Create DataFrames columns1 = ["name", "age"] df1 = spark.createDataFrame(data1, columns1) columns2 = ["name", "city"] df2 = spark.createDataFrame(data2, columns2) # Enable adaptive query execution spark.conf.set("spark.sql.adaptive.enabled", "true") # Applying Adaptive Query Execution (Runtime adaptive optimization) optimized_join = df1.join(df2, on="name") # Show the optimized join result print("Optimized Join DataFrame:") optimized_join.show() # Stop the Spark session spark.stop()
創建了兩個 DataFrame (df1 和 df2),並通過將配置參數 「spark.sql.adaptive.enabled」 設置為 「true」 來啟用自適應查詢執行功能。
自適應查詢執行允許 Spark 在執行期間根據運行時統計資訊調整查詢計劃。
程式碼在 「name」 欄位上執行 df1 和 df2 之間的聯接。
Spark 的自適應查詢執行會根據運行時統計資訊動態調整查詢計劃,從而提高性能。
Ref:
https://data-flair.training/blogs/spark-rdd-operations-transformations-actions/
https://www.geeksforgeeks.org/wide-and-narrow-dependencies-in-apache-spark/
留言
張貼留言