動作追蹤 相關論文研讀心得_Notes1
首先是
Department of Computer Science and Information Engineering National Taiwan Normal University
方瓊瑤老師 指導的學生 顏羽君
視覺式體操動作辨識系統
本計畫設計一套以電腦視覺為基礎偵測人體全身肢體動作之系統,將連續之體操運動影像輸入電腦後做肢體動作判斷辨識其動作種類或發出錯誤動作訊 息。為提升生活中資訊多元化的運用並與日常生活結合,利用攝影機拍攝動態人體行為後將影像輸入一套偵測人體各類動作之系統將會有多元化之用途。此計劃將以一台攝影機拍攝單一人物之體操運動辨識其動作及判斷是否正確,未來可運用在體育教學上將教師舞蹈動作錄製後,學生在自我練習運動動作時可即時與教師影像做比對,修正其動作之正確性;另外未來若發展為辨識手語,則利用攝影機拍攝手語,藉由判斷後翻譯手語內容,可成為身障人士與人溝通之橋樑,協助 其在遇到緊急狀況時即刻與人求救並說明情況;而休閒娛樂方面可運用在跳舞機之全身肢體偵測、Wii 的影像偵測方法。
此套系統將使用單一攝影機在室內達成辨識個人體操動作之功能,將連續彩
色影像輸入此系統後可即時判斷出動作種類,雖然單一攝影機僅可做二維平面上
之肢體動作,未來可藉由增加攝影機擴充進而辨識三維與跳躍之動作並可進行多
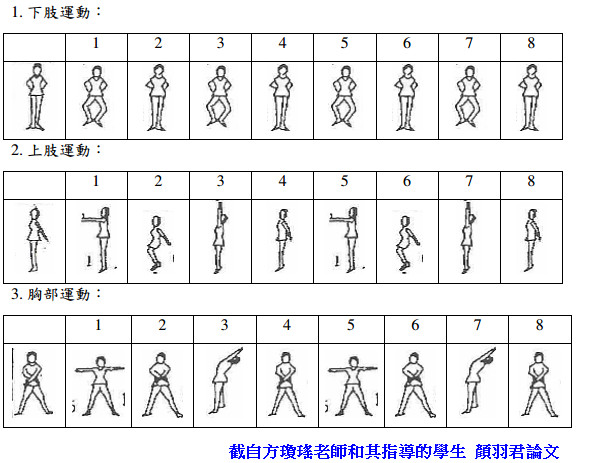
人肢體動作辨識。此套系統擬辨識由六種國民健康操動作所組合之ㄧ套體操,其
中動作共分六項,分別為下肢運動、上肢運動、胸部運動、左右彎體、四肢運動、
轉體運動,而每項動作中又各細分為幾個姿勢,當一個動作從頭至尾所有姿勢之
形狀與順序都無誤此動作才算正確。如圖一為本系統將辨識之六項國民健康體操
分解動作。

以下為他們當時五項須面對之研究困難:
1.光線因素:雖攝影地點在室內但室外光線投射入室內所造成之陰影變化、日光燈週期性閃動,以及人體體操過程中各部位造成之陰影都會造成研究上的困難。
2.背景因素:當人物跳動影響地面引起得攝影機震動會產生背景的變化,背景的改變會造成影像校正困難。另外在體育場中其他人改變動作也會造成背景的改變。
3.人物的衣著:人的姿態以及穿著的服裝會影響系統的辨識率,如果所穿著的服裝
與背景顏色太過雷同,則會提高問題的難度。
4.即時性:對於影像的分析處理,必須相當快速,否則將造成系統的實用性下降。
5.由於人體所作之運動屬於形變物體(non-rigid object)的運動,有別於其餘固形物體
(rigid objects)擁有不變的形體,要對形變物體進行動作偵測,亦為本計畫之研究
困難。
備註:
形變物體(non-rigid object) : 運動姿態會不斷改變







固形物體 (rigid objects):不變的形體
An idealization of a solid body in which deformation is neglected. In other words, the distance between any two given points of a rigid body remains constant in time regardless of external forces exerted on it. Even though such an object cannot physically exist due to relativity, objects can normally be assumed to be perfectly rigid if they are not moving near the speed of light.
In classical mechanics a rigid body is usually considered as a continuous mass distribution, while in quantum mechanics a rigid body is usually thought of as a collection of point masses.
許多關於臉部偵測的研究,乃基於電腦圖學在物體辨識(object recognition)上的研究而來。
這些模型式(model-based)或是表象式(appearance-based)的物體辨識方法,往往將目標假設成剛體物件(rigid objects)。
此假設將使該物體上的光照條件與相機的攝影角度和真實生活裡人臉的條件不同。臉部的偵測可視為一種辨識的分類問題,那就是在區別臉部區域與非臉部區域,這種分類技術可以推廣到許多不同的辨識問題上面。
不過臉部偵測技術在模式辨識(pattern recognition)及學習技術上仍存有爭議,當一個原始資料(raw data)或是經過濾器處理後之影像進入到模式分類器(pattern classifiers)時,其所具有的特徵空間(features space)是非常大的,而臉部區域與非臉部區域的分類乃根據多形分布函數(multimodal distribution functions,MDFs)以及在那些色彩空間中的非線性邊界決定機制所提供的特徵化資料為主。因此為了讓分類器達到有效的執行,分類器必須能從這些大量的訓練資料裡面進行適當的外推(extrapolate)邏輯運作,或是有效的處理這些高維度的訓練資料。
而影響到臉部偵測成功的因子有「臉部表情(facial expression)」、「姿勢(pose)」、「影像方位(image orientation)」、「結構性元件(structural components)的存在與否」、「影像解析度(image resolution)」以及「其他造影條件(imaging conditions)」…等等。
臉部偵測(facial detection)與臉部定位(facial localization)有何不同??????

臉部偵測(facial detection)與臉部定位(facial localization)是有重疊之處的,後者可視為前者的一部份集合,其為臉部偵測的簡化應用,主要假設是輸入影像只有一張臉孔存在。
另外一種臉部方面的生物辨識應用就是「臉部特徵偵測(facial features detection)」,其主要假設是輸入影像內只存在一張臉譜,並得偵測其臉部的局部特徵是否存在,
例如:眼睛、耳朵、鼻子、嘴巴、嘴唇…等等特徵。

但若是要在輸入影像內辨識使用者或是識別身分,其主要為「臉部辨識(facial recognition)」以及「臉部識別(facial identification)」的應用領域。
如果是要驗證某人的身分單一性,則使用的是「臉部驗證(facial authentication)」技術,其用來驗證輸入影像的人與電腦中所認同的使用者是否為同一人。
前面這些技術大多屬於單一輸入影像內的應用技術,如果要即時(real-time)對一連串的影像序列中(例如:視訊)對人臉部分進行位置與臉部方向進行評估,那使用的技術則稱為「臉部追蹤(face tracking)」方法。
文獻回顧與探討
一般對影像的處理及分析,首先是利用「物體追蹤」(object tracking)的技術
來追蹤動態物體,一旦我們追蹤到物體,就可以做進一步的肢體動作分析。
而目
前的物體追蹤是透過比對連續影像間物體的相似度來完成,於是物體特徵的擷
取,相似程度的判別,目標物的搜尋,都涵蓋在此議題中。
目前物體追蹤的方法
可概分成四類:
1.區域式追蹤 (Region-Based Tracking)
假設影像變動的區域即為目標物的位置, 藉著偵測這些變動區域的位置來追蹤目標物。
通常利用目前的影像與背景相減來偵測出變化的區域,然後再進一步的設立規則做篩選,合併,或劃分。
McKenna 等人[2]設計了一種可調性背景相減法(adaptive background subtraction),針對人與人群做追蹤,其追蹤層級由小而大可分為三個層次:區塊(region)、人(people)以及人群(groups),而每一個層次都可以再依照區塊色彩和表徵特性來進行合併或分解,可以達到追蹤單人或多人的效果。
此方法有其缺點,除了無法可靠地解決物體合併的問題,無法取得物體的 3D
動作外,對於雜亂有變動的背景亦不適用。圖一為兩人交錯所拍攝出支連續影
像。圖二為使用背景消去法後產生目標物的方塊。


2.主動式輪廓追蹤(Active
Contour-Based Tracking)
方法是用輪廓線(contour)來描述移動的物體,並利用輪廓線的改變進行追蹤,如[3]即使用這樣的方法。此方法的好處在於更有效率,且降低了複雜度,由於輪廓線是封閉曲線,即使物體交錯,也較容易解決。
但其缺點仍然是缺乏 3D的資訊,無法進行三度空間上的追蹤,且此演算法的追蹤效果對於初步輪廓的偵測或選取非常敏感,故較難用於全自動的偵測追蹤系統。
圗四為足球場上主動式輪廓追蹤所呈現之結果。

圖四、足球場上的動作偵測。(1a)及(1b)為兩張連續的動作,輪廓線慢慢縮小的過
程[3]。
程[3]。
3.特徵追蹤 (Feature-Based Tracking)
本方法是利用物體的特徵來進行追蹤,首先針對要追蹤的物體擷取特徵,
這些特徵可分為三種:
整體性特徵(global feature-based),如重心、色彩、面積等;
局 部 性 特 徵 ( local feature-based ) , 如 線 段 、 頂 點 等
相 依 圖 形 特 徵(dependence-graph-based),如特徵間的結構變化等。
當影像中目標物的低階特徵擷取出後,即可匯集成更高階的特徵資訊,利用比對連續影像間的高階特徵來追蹤該物體。
此方法可以用來即時追蹤多個物體(相依圖形特徵的方法除外),利用運動特徵、局部特徵或相依的結構特徵來解決物體交錯的問題,但是使用運動特徵的方法穩定性不高,而使用局部特徵的方法則比較耗時費力。此演算法的另一缺點是,用 2D 影像對物體的辨識度並不高,且通常無法還原出物體的 3D 資訊。
這些特徵可分為三種:
整體性特徵(global feature-based),如重心、色彩、面積等;
局 部 性 特 徵 ( local feature-based ) , 如 線 段 、 頂 點 等
相 依 圖 形 特 徵(dependence-graph-based),如特徵間的結構變化等。
當影像中目標物的低階特徵擷取出後,即可匯集成更高階的特徵資訊,利用比對連續影像間的高階特徵來追蹤該物體。
此方法可以用來即時追蹤多個物體(相依圖形特徵的方法除外),利用運動特徵、局部特徵或相依的結構特徵來解決物體交錯的問題,但是使用運動特徵的方法穩定性不高,而使用局部特徵的方法則比較耗時費力。此演算法的另一缺點是,用 2D 影像對物體的辨識度並不高,且通常無法還原出物體的 3D 資訊。
4.模型追蹤
(Model-Based Tracking)
模型追蹤的方法將會提供較精細與準確的判斷,因此需要良好的物體結構模型,可加入物體本身的運動特性,本質上,比較不受附近背景或其他物體干擾的影響,也較能對抗物體間交錯問題,但相對地運算量也比較大。
通常模型追蹤的 方式分成主要三步驟:
(1)建立物體模型
以人為例,建立人形的姿勢結構模型,如棒狀圖形(stick figure)(圖 五左)[4]所構成的人形。目前有愈來愈多研究偏向建立 3D 的 model,因為 2D 影像的主要缺點在於所得資訊受視角限制。Delamarre 等人[5]利用多台攝影機所得 的剪影來建立 3D 模型(圖五右)。

(2)建立運動模型
由於人體運動時四肢與關節的相對移動量不會很大,我們可以利用這些資訊來建立運動模型。建立 3D 的運動模型可以有效解決 2D 影像中物體間因為交錯而產生誤判的情況。
(3)搜尋和比對
通常模型追蹤的 方式分成主要三步驟:
(1)建立物體模型
以人為例,建立人形的姿勢結構模型,如棒狀圖形(stick figure)(圖 五左)[4]所構成的人形。目前有愈來愈多研究偏向建立 3D 的 model,因為 2D 影像的主要缺點在於所得資訊受視角限制。Delamarre 等人[5]利用多台攝影機所得 的剪影來建立 3D 模型(圖五右)。

(2)建立運動模型
由於人體運動時四肢與關節的相對移動量不會很大,我們可以利用這些資訊來建立運動模型。建立 3D 的運動模型可以有效解決 2D 影像中物體間因為交錯而產生誤判的情況。
(3)搜尋和比對
目的為從連續影像中快速且正確找出物體位置,或是建立其他模型所需要蒐集的資訊。常用 Kalman filtering、Dynamical strategies、Taylor model strategies、Stochastic sampling 的技術。
搜尋和比對的主要程序包括預測(predicting)物體的下一個狀態以縮小比對範圍,以及根據誤差更新(updating)系統的內部參數。
針對比較複雜的情況下,使用 Levenberg-Marquardt algorithm[9]的技術來解決多參數的問題。
另外,針對減少背景干擾的問題,Markov chain、Monte Carlo[10]、Genetic algorithms、condensation [11][12]等為常用的方法。
模型追蹤的方法與前三者方法相比,有幾項主要優點。
由於此演算法從影像中所取得的即為 3D 資訊,故不需再多加處理。
利用先前的 3D 資訊,可整合做為判斷下一個動作的根據,故即使物體互相交錯,也能準確地判斷。另外,此演算法在物體動作變化很大時仍可應用。
搜尋和比對的主要程序包括預測(predicting)物體的下一個狀態以縮小比對範圍,以及根據誤差更新(updating)系統的內部參數。
針對比較複雜的情況下,使用 Levenberg-Marquardt algorithm[9]的技術來解決多參數的問題。
另外,針對減少背景干擾的問題,Markov chain、Monte Carlo[10]、Genetic algorithms、condensation [11][12]等為常用的方法。
模型追蹤的方法與前三者方法相比,有幾項主要優點。
由於此演算法從影像中所取得的即為 3D 資訊,故不需再多加處理。
利用先前的 3D 資訊,可整合做為判斷下一個動作的根據,故即使物體互相交錯,也能準確地判斷。另外,此演算法在物體動作變化很大時仍可應用。



留言
張貼留言