SQL查詢效能調校經驗談(二)_表分區Partition Table

有一張table資料量累積十分龐大
跨年度累積量很可觀
)_%20-%20Micro.png)
那在耗時查詢上
)_%20-%20Micro.png)
SET STATISTICS IO ON; SET STATISTICS TIME ON; dbcc dropcleanbuffers --clear buffer SELECT * FROM [AdventureWorks2014].[Sales].[SalesOrderHeader] SET STATISTICS IO OFF; SET STATISTICS TIME OFF;
經過時間 = 420 ms左右
當資料庫中某個table的資料量爆多,在查詢資料時候會明顯感覺到速度很慢
此時可以考慮分區表
分區表是自SQL Server2005以後出現的功能,這特性允許把邏輯層面的一個table
在物理層面可分為多個部分。
Partition Table可以就物理層面去將一個大表分成幾個小表,但從邏輯層面看,還是原先那個單一個大表。(換言之,你程式碼不會有需要改動。)
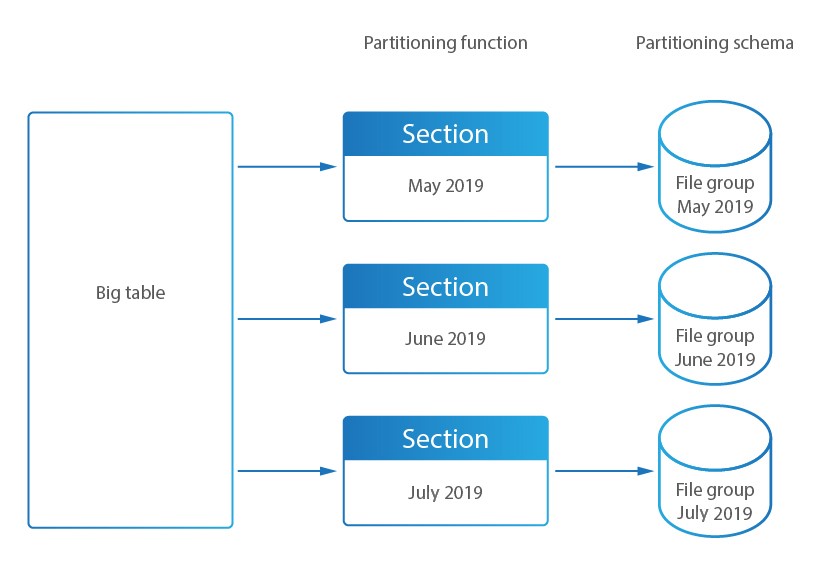
白話而言,資料會是分段的存儲,較常使用的技法是透過年分(建立的日期),對於特定當年資料做CRUD的操作。而對於較舊資料幾乎不做寫入操作只進行唯讀查詢。
這類情境可能就適合Partition Table的功用。
若對於資料操作只涉及到一部分資料而不是全部資料情況可以考慮透過分區表,若一張資料表中的data經常不管年分之類的甚至很頻繁有增刪改查操作就建議最好不要分區。
通常隨著資料增長,只使用單一個資料庫文件存放的弊端就會慢慢浮上檯面。
因此若使用多個文件分布資料到多個硬碟中可以集大提高I/O效能
再來就是對於備份和復原等操作也會輕鬆一些,尤其針對資料量略大的DB。

分區表:就邏輯層面仍算同一個(同一個檔案組)和多個的(不同檔案組)
較為透明可見的
分表:物理上分區(clone出來,因此在邏輯層面看算多個,物理層也算多個)

DB中分區其實分為
水平分表(Horizontal Partitioning):一張資料表的資料分成多個表(結構不變)

垂直分表(Vertical partitioning):將一張資料表按照欄位分成不同的表(結構發生改變)

大部分都優先推使用水平分區如此一來程式碼會比較不會有需要更動的地方
分區的意義在於去將大量資料從物理上切分為幾個互相獨立的小部分。
如此一來在查詢時候只取其中一個或者幾個分區,減少查詢資料量。
對不同的檔案組的分區,對於多CPU系統,平行查詢的效能要高於對整個table查詢的效能!
單一張大表直接查有可能導致速度大幅度下降(可能幾萬,幾十萬,幾千萬筆)
就可透過採取分區分表來將大表拆分小表解決。
也能類似透過案月份,年分分表最終在用View視圖來將小表重新整併一個虛擬表。
分區表資料主要存放於分區檔案中(ndf)當中
分區檔案則是存放於分區組(檔案組)當中
分區檔案組則是存放於一或多個硬碟中
備註:
微軟的SQL Server 分三種檔案類型
mdf 主要資料檔案(副檔名.mdf是 primary data file 的縮寫)
ndf 次要資料檔案(是可有可無的),由使用者定義並存儲使用者資料。通過將每個檔案放在不同的磁碟驅動器上,次要檔案可用於將資料分散到多個磁碟上。若資料庫超過了單個 Windows 檔案的最大大小,可以使用次要資料檔案,這樣資料庫就能繼續增長。
ldf 事務(交易)日誌 (副檔名.ldf是Log data files的縮寫)
創建分區表主要步驟可分為
1.建立資料庫文件群組
2.建立資料庫文件
3.建立分區函數
4.建立分區配置(方案)
5.建立分區表
在此我拆分四個時間間隔
2011,2012,2013,2014
2011之前的 , 2011~2012 , 2012~2013 , 2013~2014, 2014之後的
因此共分5個檔案組分區
1.建立資料庫文件群組
針對資料庫右鍵屬性
)_%20-%20Micro.png)
檔案群組這裡可以去新擴充
那就以年分2011,2012,....2015各自分5個filegroup

2.建立資料庫文件
在文件(檔案)這裡也相應新增5個對應檔案


3.建立分區函數
緊接著要創建分區函數
)_%20-%20Micro.png)
)_%20-%20Micro.png)
)_%20-%20Micro.png)
這裡底下記得勾選起來


4.建立分區配置(方案)



在此左邊界跟右邊界主要差異在於
左邊界(<=)
右邊界(<)

這裡就先採用左邊界來劃分
5.建立分區表

在這裡可以選立即執行
這裡我想看底層產生的T-SQL script

程式碼
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | USE [AdventureWorks2014] GO BEGIN TRANSACTION CREATE PARTITION FUNCTION [function_orderdate](datetime) AS RANGE LEFT FOR VALUES (N'2011-01-01T00:00:00', N'2012-01-01T00:00:00', N'2013-01-01T00:00:00', N'2014-01-01T00:00:00') CREATE PARTITION SCHEME [schema_orderdata] AS PARTITION [function_orderdate] TO ([fg2011], [fg2012], [fg2013], [fg2014], [fg2015]) ALTER TABLE [Sales].[SalesOrderHeader] DROP CONSTRAINT [PK_SalesOrderHeader_SalesOrderID] WITH ( ONLINE = OFF ) ALTER TABLE [Sales].[SalesOrderHeader] ADD CONSTRAINT [PK_SalesOrderHeader_SalesOrderID] PRIMARY KEY NONCLUSTERED ( [SalesOrderID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY] CREATE CLUSTERED INDEX [ClusteredIndex_on_schema_orderdata_638089821953947046] ON [Sales].[SalesOrderHeader] ( [OrderDate] )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [schema_orderdata]([OrderDate]) DROP INDEX [ClusteredIndex_on_schema_orderdata_638089821953947046] ON [Sales].[SalesOrderHeader] COMMIT TRANSACTION |
當該大表已經創建好分區
會發現反灰已經不能再創建分區了
)%20-%20Micro.png)
再下方儲存體也可以看到新產生的相關內容
)_%20-%20Micro.png)
我們也可透過如下t-sql來查看
檔案跟檔案組分區資訊
1 2 3 4 5 6 7 8 9 | SELECT df.[name], df.physical_name, df.[size], df.growth, f.[name] [filegroup], f.is_default FROM sys.database_files df JOIN sys.filegroups f ON df.data_space_id = f.data_space_id; |
)_%20-%20Micr.png)
查看分區資訊和row數
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | -- 查看表分區及分區列數 select convert(varchar(50), ps.name ) as partition_scheme, p.partition_number, convert(varchar(10), ds2.name ) as filegroup, convert(varchar(19), isnull(v.value, ''), 120) as range_boundary, str(p.rows, 9) as rows from sys.indexes i join sys.partition_schemes ps on i.data_space_id = ps.data_space_id join sys.destination_data_spaces dds on ps.data_space_id = dds.partition_scheme_id join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id join sys.partitions p on dds.destination_id = p.partition_number and p.object_id = i.object_id and p.index_id = i.index_id join sys.partition_functions pf on ps.function_id = pf.function_id LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_id and v.boundary_id = p.partition_number - pf.boundary_value_on_right WHERE i.object_id = object_id('Sales.SalesOrderHeader')--分割區資料表名稱 and i.index_id in (0, 1) order by p.partition_number GO |
)_%20-%20Micr.png)
其餘常用查詢
1 2 3 | SELECT * from sys.partition_functions --//分區函數(包含SQL Server中每個資料分割函數的資料列。) select * from sys.partition_range_values --//分區配置(針對 R 類型資料分割函數的每個範圍界限值,各包含一個資料列。) select * from sys.partition_schemes --//針對每個資料空間包含一個資料分割配置的資料列 |
)_%20-%20Micr.png)
Ref:
https://www.mssqltips.com/sqlservertip/1200/handling-large-sql-server-tables-with-data-partitioning/
https://www.cathrinewilhelmsen.net/table-partitioning-in-sql-server/
https://www.sqlskills.com/resources/whitepapers/partitioning%20in%20sql%20server%202005%20beta%20ii.htm
https://www.datasunrise.com/professional-info/what-is-partitioning/
https://logicalread.com/partition-tables-sql-server-perf-dn01/#.Y7ybnXZBxPY
https://www.sqlshack.com/database-table-partitioning-sql-server/
https://medium.com/@MadhavanR51/how-to-merge-partitions-in-sql-server-cb125701fd41
https://sqlperformance.com/2013/07/t-sql-queries/aggregates-and-partitioning
https://ithelp.ithome.com.tw/articles/10227066
https://blog.csdn.net/yetugeng/article/details/83412087
https://dotblogs.com.tw/ricochen/2012/05/04/71971



留言
張貼留言