Apache Hive筆記(一)_Hive分散式資料倉儲系統介紹_Hive CLI和beeline CLI

Hive
是Hadoop當中一個極重要的子專案,與HDFS協同合作成為Hadoop上的資料倉儲架構,Hive提供相近於T-SQL的查詢語言稱為Hive QL。
Hive QL提供使用者執行部份與SQL類似的操作,如常見的資料定義(DDL)操作及資料操
作語言(DML)等
目前Hive QL並不完全支援目前SQL提供的所有的函式,如預存程序與觸發程序等。與Hadoop中的MapReduce程式技術結合後,可自動的將Hive QL語言轉换為MapReduce Task,使用者可容易的使用Hive QL對HDFS中的海量資料進行分析處理,不需要再以Java語言自行撰寫MapReduce程式。
目前Hive提供透過JDBC與ODBC及Thrift等方式來與Hive進行連接

Thrift是Facebook在2007年交給Apache軟體基金會的開源專案,主要目的是為了解決Facebook在不同系統中大資料量的傅輸通訊,及系統之間所使用的不同軟體語言與異質環境而訂定的跨平台軟體服務,其支援C++、C#、Haskell、Java、Ocami、Per、PHP、Python、Ruby、Smalltalk等多種不同的程式語言間的通訊,並可作為二進位的高性能的通訊中介軟體,支援資料及物件的序列化和多種類型的RPC服務etaStore為Hive的系統目錄架構,負責Hive中介資料的存放,如資料表的格式、屬性等,因Hive儲存建立在HDFS架構上,在Hive下每張資料表實體存放位置皆會對應到HDFS中的檔案目錄。
Hive提供使用者兩種操作模式為Web UI及命令列介面,來進行對Hive執行Hive QL指令,
Hive QL對MetaStore的中介資料進行分析後,透過Driver中的编譯器轉换為
MapReduce Task後,將該工作交給Hadoop進行資料處理。

Apache Hive 是一種容錯的分散式資料倉儲系統,可進行大規模分析。資料倉儲提供資訊的中央存放區,可以輕鬆分析資料以作出明智且資料導向的決策。Hive 讓客戶使用 SQL 讀取、寫入與管理 PB 級資料。
Hive 建構在 Apache Hadoop 之上,這是一個用於有效儲存和處理大型資料集的開源框架。因此,Hive 與 Hadoop 密切整合,並且旨在快速處理 PB 的資料。Hive 獨一無二之處是能夠利用 Apache Tez 或 MapReduce 查詢大型資料集,並具有類似 SQL 的介面。
Hive 是為了允許熟悉 SQL 的非程式設計師使用類似 SQL 的介面,使用稱為 HiveQL 類似的 SQL 介面處理資料。傳統關聯式資料庫專為對中小型資料集進行互動式查詢而設計,並且不能很好處理大量資料集。Hive 是使用批次處理,以便在非常大的分散式資料庫中快速執行。
Hive配置文檔目錄下內容
[cloudera@cdh6 ~]$ ls -l /etc/hive/conf/
total 64
-rw-r--r-- 1 root root 20 Jan 31 2023 __cloudera_generation__
-rw-r--r-- 1 root root 70 Jan 31 2023 __cloudera_metadata__
-rw-r--r-- 1 root root 3656 Jan 31 2023 core-site.xml
-rw-r--r-- 1 root root 617 Jan 31 2023 hadoop-env.sh
-rw-r--r-- 1 root root 1705 Jan 31 2023 hdfs-site.xml
-rw-r--r-- 1 root root 2655 Jan 31 2023 hive-env.sh
-rw-r--r-- 1 root root 6493 Jan 31 2023 hive-site.xml
-rw-r--r-- 1 root root 310 Jan 31 2023 log4j.properties
-rw-r--r-- 1 root root 5299 Jan 31 2023 mapred-site.xml
-rw-r--r-- 1 root root 1661 Jan 31 2023 redaction-rules.json
-rw-r--r-- 1 root root 315 Jan 31 2023 ssl-client.xml
-rw-r--r-- 1 root root 190 Jan 31 2023 topology.map
-rwxr-xr-x 1 root root 1594 Jan 31 2023 topology.py
-rw-r--r-- 1 root root 3674 Jan 31 2023 yarn-site.xml
[cloudera@cdh6 ~]$

找尋Hive Default資料庫的預設位置
(不同版本的預設位置可能不同)
[cloudera@cdh6 ~]$ cat /etc/hive/conf/hive-site.xml | grep warehouse.dir -B 1 -A 2
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
[cloudera@cdh6 ~]$

Hive的預設資料庫(default)的HDFS目錄位置
/user/hive/warehouse
位在Hive default資料庫的表格
預設每一個表格對應於此目錄下的子目錄,子目錄名字等於表格名字
對照Cloudera Manager

hive指令與beeline指令
hive指令:
- 直接連線到Hadoop Cluster(同時具有hive metadstore與hadoop cluster客戶端的身分)
- 這是 Hive 的原始命令行工具,用於直接與 Hive 進行互動。
- 使用 Hive CLI,用戶可以執行 HiveQL 語句,如創建表、執行查詢等。它運行在 HiveServer1 上,直接與元數據庫通信。
- Hive CLI 直接運行在用戶端,並與後端的 Hive 服務器進行互動,這可能導致安全性和維護性的問題。
beeline指令:
- 連線到Hive2 Server(beeline只是hive2 server的client端,不需要連線到hadoop cluster)
- 由hive2 server執行HQL產生MR/Spark JOB並submit到Hadoop Cluster執行。
- 這是一個基於 JDBC 的 Hive 命令行工具,用於與 HiveServer2 互動。
- Beeline 通過JDBC連接到HiveServer2,提供了一種更安全、可靠方式來執行 Hive 查詢。
[cloudera@cdh6 ~]$ which hive
/usr/bin/hive
[cloudera@cdh6 ~]$ which beeline
/usr/bin/beeline
[cloudera@cdh6 ~]$

HiveServer
HiveServer是 Apache Hive 提供的一種服務,它允許客戶端使用多種支持的協議來執行 HiveQL 查詢。主要有兩個版本分別為HiveServer1 和 HiveServer2。
對於 HiveServer1,通常可以直接通過 Hive CLI 連接
# 檢查 HiveServer1
ps -ef | grep HiveServer1
# 檢查 HiveServer2
ps -ef | grep HiveServer2

[cloudera@cdh6 ~]$ ps -ef | grep HiveServer1
cloudera 27894 23727 0 15:51 pts/2 00:00:00 grep --color=auto HiveServer1
[cloudera@cdh6 ~]$ ps -ef | grep HiveServer2
hive 4518 4093 0 Dec28 ? 00:01:19 /usr/java/jdk1.8.0_232-cloudera/bin/java -Dproc_jar -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Xms52428800 -Xmx52428800 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hive_hive-HIVESERVER2-6c57b1a598e149581e1d58acf4880987_pid4518.hprof -XX:OnOutOfMemoryError=/opt/cloudera/cm-agent/service/common/killparent.sh -Dlog4j.configurationFile=hive-log4j2.properties -Dlog4j.configurationFile=hive-log4j2.properties -Djava.util.logging.config.file=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/bin/../conf/parquet-logging.properties -Dyarn.log.dir=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/logs -Dyarn.log.file=hadoop.log -Dyarn.home.dir=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/libexec/../../hadoop-yarn -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/lib/native -Dhadoop.log.dir=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop -Dhadoop.id.str=hive -Dhadoop.root.logger=INFO,console -Dhadoop.policy.file=hadoop-policy.xml -Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.util.RunJar /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/hive-service-2.1.1-cdh6.3.2.jar org.apache.hive.service.server.HiveServer2 --hiveconf hive.aux.jars.path=file:///opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/auxlib/hive-exec-2.1.1-cdh6.3.2-core.jar,file:///opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/auxlib/hive-exec-core.jar
cloudera 27903 23727 0 15:51 pts/2 00:00:00 grep --color=auto HiveServer2
[cloudera@cdh6 ~]$
[cloudera@cdh6 ~]$ hdfs dfs -ls /user/hive
Found 1 items
drwxrwxrwt - hive hive 0 2020-09-04 17:03 /user/hive/warehouse

Hive CLI進入
直接連線到Hadoop Cluster,所以此主機也必須是Hadoop客戶端。
[cloudera@cdh6 ~]$ hive
WARNING: Use "yarn jar" to launch YARN applications.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-common-2.1.1-cdh6.3.2.jar!/hive-log4j2.properties Async: false
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive>
官方建議改用beeline連線到HiveServer2

hive> show databases;
OK
default
Time taken: 0.315 seconds, Fetched: 1 row(s)
hive> create database db1;
OK
Time taken: 0.204 seconds
hive> show databases;
OK
db1
default
Time taken: 0.161 seconds, Fetched: 2 row(s)
hive> select current_database();
OK
default
Time taken: 0.478 seconds, Fetched: 1 row(s)
hive> use db1;
OK
Time taken: 0.023 seconds
hive> select current_database();
OK
db1
Time taken: 0.083 seconds, Fetched: 1 row(s)
hive> !q
> quit();
Exception raised from Shell command Failed to execute q
quit()
hive> quit;
[cloudera@cdh6 ~]$ hdfs dfs -ls /user/hive/warehouse/
Found 4 items
drwxrwxrwt - cloudera hive 0 2024-12-29 13:46 /user/hive/warehouse/db1.db
drwxrwxrwt - admin hive 0 2020-09-03 16:32 /user/hive/warehouse/sample_07
drwxrwxrwt - admin hive 0 2020-09-03 16:32 /user/hive/warehouse/sample_08
drwxrwxrwt - admin hive 0 2020-09-03 16:32 /user/hive/warehouse/web_logs
[cloudera@cdh6 ~]$
beeline CLI進入
beeline只連線到Hive2 Server,之後由Hive2 Server連線到Hadoop Cluster。
[cloudera@cdh6 ~]$ beeline -u jdbc:hive2://cdh6:10000 -n cloudera

顯示所連線的Hive Server有哪些資料庫存在
0: jdbc:hive2://cdh6:10000> show databases;
登入後,預設位置在default資料庫
0: jdbc:hive2://cdh6:10000> select current_database();
目前所在資料庫裡有那些表格存在
0: jdbc:hive2://cdh6:10000> show tables;

Hive CLI創建table並透過desc指令查看table結構
hive> create table t1
> (col1 int,col2 varchar(10))
> row format delimited
> fields terminated by ','
> stored as textfile;
OK
Time taken: 1.639 seconds
hive> desc t1;
OK
col1 int
col2 varchar(10)
Time taken: 0.235 seconds, Fetched: 2 row(s)
hive>

beeline CLI透過desc指令查看table結構
0: jdbc:hive2://cdh6:10000> desc t1;
INFO : Compiling command(queryId=hive_20241229164041_8ea3659b-0225-49d1-b049-082ed0fd0a7b): desc t1
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col_name, type:string, comment:from deserializer), FieldSchema(name:data_type, type:string, comment:from deserializer), FieldSchema(name:comment, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hive_20241229164041_8ea3659b-0225-49d1-b049-082ed0fd0a7b); Time taken: 0.206 seconds
INFO : Executing command(queryId=hive_20241229164041_8ea3659b-0225-49d1-b049-082ed0fd0a7b): desc t1
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hive_20241229164041_8ea3659b-0225-49d1-b049-082ed0fd0a7b); Time taken: 0.044 seconds
INFO : OK
+-----------+--------------+----------+
| col_name | data_type | comment |
+-----------+--------------+----------+
| col1 | int | |
| col2 | varchar(10) | |
+-----------+--------------+----------+
2 rows selected (0.416 seconds)
0: jdbc:hive2://cdh6:10000>
0: jdbc:hive2://cdh6:10000> desc formatted t1;
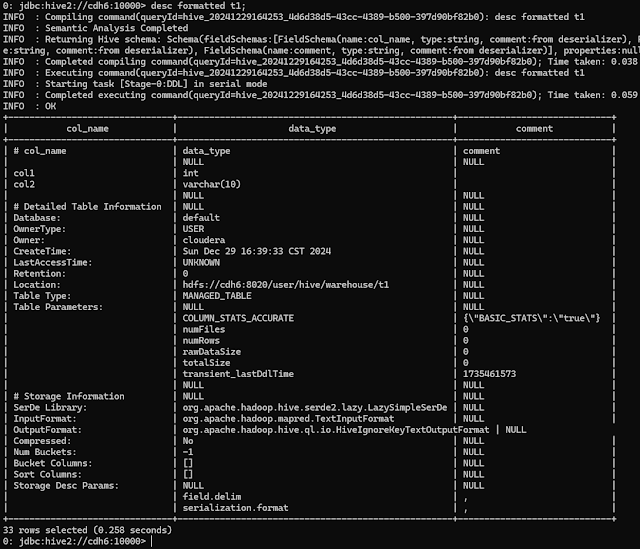
0: jdbc:hive2://cdh6:10000> select * from t1;
INFO : Compiling command(queryId=hive_20241229164441_d6147638-c6d2-4609-a354-3b8912751f67): select * from t1
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t1.col1, type:int, comment:null), FieldSchema(name:t1.col2, type:varchar(10), comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20241229164441_d6147638-c6d2-4609-a354-3b8912751f67); Time taken: 0.08 seconds
INFO : Executing command(queryId=hive_20241229164441_d6147638-c6d2-4609-a354-3b8912751f67): select * from t1
INFO : Completed executing command(queryId=hive_20241229164441_d6147638-c6d2-4609-a354-3b8912751f67); Time taken: 0.0 seconds
INFO : OK
+----------+----------+
| t1.col1 | t1.col2 |
+----------+----------+
+----------+----------+
No rows selected (0.123 seconds)
0: jdbc:hive2://cdh6:10000>

Ref:
https://hive.apache.org/
https://aws.amazon.com/tw/what-is/apache-hive/
https://data-flair.training/blogs/apache-hive-architecture/
https://ithelp.ithome.com.tw/articles/10194882



留言
張貼留言