HDFS指令和cloudera manager網頁管理介面筆記

HDFS
是Apache Hadoop 其中核心,為分散式的檔案系統。
因具有高容錯性的特點,適合建立在低成本的商業設備上。
其設計理念是支持在低價硬件上運用分散式的儲存架構,達到高容錯性 (fault-tolerant)、高吞吐量 (high throughput)。
優點:
採用分散式架構,搜尋、讀取資料快速。
多台機器都有備份,資料不易消失。
缺點:
在寫入資料速度緩慢,因其架構設計是以一次寫入多次讀取。
HDFS Read流程圖
在讀取時,可從好幾個Data Node做存取,來快速獲取資料。

HDFS Write流程圖
但寫入時候,寫到某一個Data Node之外,還要做資料複製,備份後還需要等待ACK。
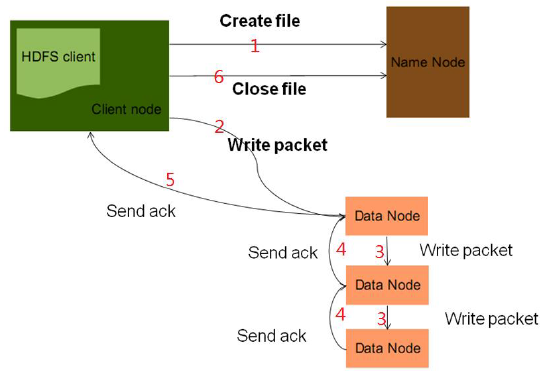
HDFS結構上採取Master/Slave架構,如下面示意圖所示,HDFS的叢集建置由一個NameNode和數個DataNode組成。通常每個Node都包含一個Name Node或Data Node。也可以在同一台機器上有多個Data Node但很少這麼做。

NameNode
是一個控制所有Data Node行為主控端,資料不會透過它傳送,但會保存哪個Data Node有哪些資料的資訊,俗稱metadata,也可控制Client端對資料存取。
更重要的就是NameNode還控制Name Space,所謂Name Space就是讓使用者看到的HDFS只是一大塊空間,可在裡面創建資料,使用者並不知道實際上資料被存放到哪個node,更不知道真實路徑,只會知道在HDFS裡面的路徑,真實資料就存在Name Node當中,包括所有備份檔位置。
HDFS在有資料請求情況下會由 NameNode(Master)下的中間資料來進行對DataNode(Slave)的資料存取。

Cloudera Distribution Hadoop (CDH)
是 Cloudera 公司推出的 Big Data Solution,目的是為了讓各個企業能夠輕鬆部署自己的 Cloud,讓更多公司能夠導入 Hadoop 資來做使用,減低入門門檻。此外CDH 是屬於Apache 眾多的 Open Source Project之一。
CDH 包含了 Hadoop、HBase、Hive、Pig、Impala、Spark,使用者不需要像之前要一個個系統去建立安裝,先安裝好CDH,之後直接把其他要用的軟體裝在同一個系統上,安裝方式是以套件方式裝在CDH上,因此也比本來建立整個系統來得簡單且不容易失敗。此外安裝好就有管理介面可用,方便使用者進行資料管理。

cloudera manager網頁管理介面
(另外一套Apache Ambari也是類似網頁管理工具,是開源的。)
(另外一套Apache Ambari也是類似網頁管理工具,是開源的。)
Cloudera Manager是Cloudera專門for Hadoop所釋出的管理工具,分免費與企業版本。





在 Hadoop 的 HDFS 架構中,NameNode 是核心元件之一。
它的兩個主要 Port 分別具有不同的用途:
一個是8020的 RPC port
用於 DataNode 和 NameNode 之間的內部通信。
客戶端(例如 Hadoop 的 FileSystem API 或 CLI)會通過這個 Port 與 NameNode 交互,執行文件系統相關的操作(例如讀寫文件、創建目錄、刪除文件等)。
負責處理 Hadoop Distributed File System (HDFS) 的 RPC(Remote Procedure Call)請求。
一個是web ui port
CDH5版本50070 (Hadoop 1.x)
CDH6版本9870 (Hadoop 2.x 及以上版本)
提供 Web 介面,讓用戶可以通過瀏覽器查看 HDFS 的狀態和統計信息。
支援用戶檢視文件系統的目錄結構、DataNode 的狀態、內存使用情況、複製因數等。
適用於系統監控和管理。
通常可以在 Hadoop 配置檔案(如 core-site.xml 和 hdfs-site.xml)中找到相關設定。
Hadoop 配置檔案路徑確認
ls -l /etc/hadoop/conf/
cat /etc/hadoop/conf/core-site.xml
cat /etc/hadoop/conf/hdfs-site.xml


其他配置檔路徑
Spark:
ls -l /etc/spark/conf/
Hive:
ls -l /etc/hive/conf/
Apache Flume:
ls -l /etc/flume-ng/conf/

目前登入的os user資訊

查看hdfs block的副本個數(正式環境建議要設置至少3個)
cat /etc/hadoop/conf/hdfs-site.xml | grep replication -A 1

cat /etc/hadoop/conf/core-site.xml | grep defaultFS -B 1 -A 2

hdfs dfs -ls hdfs://cdh6:8020/user/cloudera

查看HDFS幫助文檔
hdfs --help

hdfs跟yarn本身底層都是一個shell檔案運行



關於hdfs dfs 跟hadoop dfs差異?
指令同等紀錄
hadoop fs = hdfs dfs
hadoop jar = yarn jar
fs是檔案系統, dfs是分散式檔案系統。
在 Hadoop 的文件系統操作中
hdfs dfs :
Hadoop 2.x 及以上,推薦使用,標準化操作方式,專注於 HDFS。
- 專門用於與 HDFS(Hadoop Distributed File System) 進行互動。
- 提供與 HDFS 文件系統的操作指令,例如:
創建目錄、上傳文件到 HDFS、下載文件、檢視文件內容等。
hdfs dfs -ls / # 列出 HDFS 根目錄下的文件和目錄
hdfs dfs -put localfile /hdfs/path # 將本地文件上傳到 HDFS
hdfs dfs -get /hdfs/path localfile # 從 HDFS 下載文件到本地
hadoop dfs :
Hadoop 1.x在使用的指令,已被標記為過時(deprecated)。

陳列hdfs家目錄清單
hdfs dfs -ls 是 Hadoop 中用於檢視 HDFS(Hadoop Distributed File System) 目錄內容的指令,類似於 Linux 中的 ls 命令。它能幫助我們了解目錄下的文件結構、屬性、權限等詳細資訊。
hdfs dfs -ls
hdfs dfs -ls /user/cloudera
對照web UI

明確要求顯示某個HDFS目錄
(是否能夠成功顯示,要看當前使用者權限有無滿足所要查看HDFS目錄的權限設定)
因Hadoop無自己的身分驗證系統,所以會仰賴hadoop client端所提供的os user當作hadoop user。
在HDFS下,最高權限者為hdfs,不是root!
hdfs dfs -ls /
hdfs dfs -ls /user/

上傳本地端檔案到HDFS
hdfs dfs -put localfile remotefile

該檔案200M(預設HDFS blocksize若為128M,則此檔案將被分成2個HDFS block)
HDFS 建議使用情境應該要是大量的大檔案(至少>=100MB),而非即大量的小檔案所組成。

第二個區塊

再上傳一個檔案從web 介面跟指令確認上傳成功與否

以這個檔案較大,會拆分成比較多個Block。

從HDFS將一個目錄下載到Local Filesystem的一個目錄
hdfs dfs -get 目標檔案名稱





因為HDFS(Hadoop Distributed File System) 和 本地文件系統(Local File System) 是兩個完全不同的文件系統。終端的 cd 命令操作的是本地文件系統。因此,無法直接使用 cd 切換到 HDFS 路徑。

hdfs fsck 指令
hdfs fsck [path] [options]
hdfs fsck 是 Hadoop 中的一個診斷命令,用於檢查 HDFS 文件系統的健康狀態。它可以幫助你分析文件的狀態,檢查數據是否損壞、不一致,或者是否存在丟失的塊。是一個readonlt命令,執行時不會對 HDFS 進行任何更改。
檢查 /user/cloudera 目錄的健康狀況
hdfs fsck /user/cloudera
返回文件的複製因子、塊分佈和丟失的塊。

Status :文件系統狀態,可能是 HEALTHY 或有問題(如損壞或丟失塊)。
Total size :文件的總大小(字節)。
Total dirs :目錄的總數量。
Total files :文件的總數量。
Total blocks :檢查的塊數量。
Under-replicated blocks :複製因子不足的塊數量。
Over-replicated blocks :複製因子超過要求的塊數量。
Corrupt blocks :損壞的塊數量(需要關注)。
Missing replicas :丟失的塊副本數量。
顯示HDFS file的組成區塊
hdfs fsck -blocks -files /user/cloudera/spark-2.4.0-bin-hadoop2.7.tgz

每個hdfs block其實是data node主機local filesystem的一個檔案
建立一個HDFS目錄
hdfs dfs -mkdir testdir

為何我用hdfs dfs -ls /user/cloudera有列出但是在終端嘗試要cd到 /user/cloudera不會成功?

從HDFS將HDFS file內容顯示在hdfs工具的客戶端
hdfs dfs -cat
hdfs dfs -cat emp1.csv

DataNode資料(HDFS block)存放位置預設放在/dfs/dn

使用webHDFS陳列目錄(返回REST API JSON) 跟 hdfs對照
curl http://cdh6:9870/webhdfs/v1/user/cloudera?op=liststatus
hdfs dfs -ls

要特別留意,當使用webHDFS時,http所連線的主機為NameNode(Active)的webUI port。
使用Cloudera Manager啟動flume
Cluser 1 -> Flume -> Instances -> "Agent" + start





Flume Agent所監聽的source port
使用netcat客戶端(nc)連線到localhost:9999。打印訊息做測試會返回OK。

也可透過WEB UI去查看。

Cluser 1 -> Flume -> Instances -> Agent -> Logs -> Role log file

Q1.Which is a processing unit of Hadoop and an important core component of the Hadoop framework?
Hadoop Common
(O)MapReduce
Hadoop Distributed File System (HDFS)
Yet Another Resource Negotiator (YARN)
解析:
MapReduce is a processing unit of Hadoop. It processes data by splitting large amounts into smaller units and processing them simultaneously.
Q2.Which of the following components are included in Hadoop? Select all that apply.
Apache Cassandra
(O)Hadoop Distributed File System (HDFS)
(O)MapReduce
(O)Yet Another Resource Negotiator (YARN)
解析:
HDFS is a core component that stores the data collected from the ingestion and distributes the data across multiple nodes.
MapReduce is used to make big data manageable by processing them in clusters.
YARN is the resource manager across clusters.
Q3.What is the default block size in Hadoop?
126 megabytes
(O)128 megabytes
132 megabytes
200 megabytes
解析:
The default block size in Hadoop is 128 megabytes. This block size
determines how data is divided and stored across the Hadoop cluster.
Cloudera Manager is a management application for Hadoop clusters
Cloudera Manager管理控制台
管理大象的好幫手-Cloudera Manager
hadoop fs、hadoop dfs、hdfs dfs的差別
https://how64bit.com/categories/hadoop/
ssh cloudera@192.168.56.103



留言
張貼留言