PySpark_命令sc(SparkContext)與spark(SparkSession)_SparkSQL跟DataFrameAPI比較

進到core spark入口(建立SparkContext)
指令如下:
sc
若是要進入到SparkSession
指令如下
spark
- SparkSession封裝了SparkSession的執行環境,為所有Spark SQL程式進入點。
- 是在Spark1.6時候引入,允許不同使用者在使用不同config、暫存表情況下,共享同一個cluster環境。
- 一個Spark Application只可擁有一個SparkContext,但可有多個SparkSession。
Using Python version 2.7.5 (default, Apr 2 2020 13:16:51)
SparkSession available as 'spark'.
>>> sc
<SparkContext master=yarn appName=PySparkShell>
>>> dir(sc)
['PACKAGE_EXTENSIONS', '__class__', '__delattr__', '__dict__', '__doc__', '__enter__', '__exit__', '__format__', '__getattribute__', '__getnewargs__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_accumulatorServer', '_active_spark_context', '_batchSize', '_callsite', '_checkpointFile', '_conf', '_dictToJavaMap', '_do_init', '_encryption_enabled', '_ensure_initialized', '_gateway', '_getJavaStorageLevel', '_initialize_context', '_javaAccumulator', '_jsc', '_jvm', '_lock', '_next_accum_id', '_pickled_broadcast_vars', '_python_includes', '_repr_html_', '_serialize_to_jvm', '_temp_dir', '_unbatched_serializer', 'accumulator', 'addFile', 'addPyFile', 'appName', 'applicationId', 'binaryFiles', 'binaryRecords', 'broadcast', 'cancelAllJobs', 'cancelJobGroup', 'defaultMinPartitions', 'defaultParallelism', 'dump_profiles', 'emptyRDD', 'environment', 'getConf', 'getLocalProperty', 'getOrCreate', 'hadoopFile', 'hadoopRDD', 'master', 'newAPIHadoopFile', 'newAPIHadoopRDD', 'parallelize', 'pickleFile', 'profiler_collector', 'pythonExec', 'pythonVer', 'range', 'runJob', 'sequenceFile', 'serializer', 'setCheckpointDir', 'setJobDescription', 'setJobGroup', 'setLocalProperty', 'setLogLevel', 'setSystemProperty', 'show_profiles', 'sparkHome', 'sparkUser', 'startTime', 'statusTracker', 'stop', 'textFile', 'uiWebUrl', 'union', 'version', 'wholeTextFiles']
>>> spark
<pyspark.sql.session.SparkSession object at 0x7f99a0c3cdd0>
>>> dir(spark)
['Builder', '__class__', '__delattr__', '__dict__', '__doc__', '__enter__', '__exit__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_convert_from_pandas', '_createFromLocal', '_createFromRDD', '_create_from_pandas_with_arrow', '_create_shell_session', '_get_numpy_record_dtype', '_inferSchema', '_inferSchemaFromList', '_instantiatedSession', '_jsc', '_jsparkSession', '_jvm', '_jwrapped', '_repr_html_', '_sc', '_wrapped', 'builder', 'catalog', 'conf', 'createDataFrame', 'newSession', 'range', 'read', 'readStream', 'sparkContext', 'sql', 'stop', 'streams', 'table', 'udf', 'version']
>>> dir(spark.read)
['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_df', '_jreader', '_set_opts', '_spark', 'csv', 'format', 'jdbc', 'json', 'load', 'option', 'options', 'orc', 'parquet', 'schema', 'table', 'text']
>>>
DataFrame封裝豐富的諸多API

>>> dir(empDF)
['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattr__', '__getattribute__', '__getitem__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_collectAsArrow', '_jcols', '_jdf', '_jmap', '_jseq', '_lazy_rdd', '_repr_html_', '_sc', '_schema', '_sort_cols', '_support_repr_html', 'agg', 'alias', 'approxQuantile', 'cache', 'checkpoint', 'coalesce', 'colRegex', 'collect', 'columns', 'corr', 'count', 'cov', 'createGlobalTempView', 'createOrReplaceGlobalTempView', 'createOrReplaceTempView', 'createTempView', 'crossJoin', 'crosstab', 'cube', 'describe', 'distinct', 'drop', 'dropDuplicates', 'drop_duplicates', 'dropna', 'dtypes', 'exceptAll', 'explain', 'fillna', 'filter', 'first', 'foreach', 'foreachPartition', 'freqItems', 'groupBy', 'groupby', 'head', 'hint', 'intersect', 'intersectAll', 'isLocal', 'isStreaming', 'is_cached', 'join', 'limit', 'localCheckpoint', 'na', 'orderBy', 'persist', 'printSchema', 'randomSplit', 'rdd', 'registerTempTable', 'repartition', 'repartitionByRange', 'replace', 'rollup', 'sample', 'sampleBy', 'schema', 'select', 'selectExpr', 'show', 'sort', 'sortWithinPartitions', 'sql_ctx', 'stat', 'storageLevel', 'subtract', 'summary', 'take', 'toDF', 'toJSON', 'toLocalIterator', 'toPandas', 'union', 'unionAll', 'unionByName', 'unpersist', 'where', 'withColumn', 'withColumnRenamed', 'withWatermark', 'write', 'writeStream']
>>> type(empDF)
<class 'pyspark.sql.dataframe.DataFrame'>
>>>
假使我們有emp.csv具有表頭。

DataFrame中讀取跟顯示(從CSV檔案產生DataFrame)
spark.read.csv()預設為header=False,表示整個csv內容都是資料。

>>> empDF = spark.read.csv('emp.csv')
>>> empDF.show()
+-----+------+---------+----+---------+----+----+------+
| _c0| _c1| _c2| _c3| _c4| _c5| _c6| _c7|
+-----+------+---------+----+---------+----+----+------+
|EMPNO| ENAME| JOB| MGR| HIREDATE| SAL|COMM|DEPTNO|
| 7839| KING|PRESIDENT|null|17-NOV-81|5000|null| 10|
| 7698| BLAKE| MANAGER|7839|01-MAY-81|2850|null| 30|
| 7782| CLARK| MANAGER|7839|09-JUN-81|2450|null| 10|
| 7566| JONES| MANAGER|7839|02-APR-81|2975|null| 20|
| 7788| SCOTT| ANALYST|7566|19-APR-87|3000|null| 20|
| 7902| FORD| ANALYST|7566|03-DEC-81|3000|null| 20|
| 7369| SMITH| CLERK|7902|17-DEC-80| 800|null| 20|
| 7499| ALLEN| SALESMAN|7698|20-FEB-81|1600| 300| 30|
| 7521| WARD| SALESMAN|7698|22-FEB-81|1250| 500| 30|
| 7654|MARTIN| SALESMAN|7698|28-SEP-81|1250|1400| 30|
| 7844|TURNER| SALESMAN|7698|08-SEP-81|1500| 0| 30|
| 7876| ADAMS| CLERK|7788|23-MAY-87|1100|null| 20|
| 7900| JAMES| CLERK|7698|03-DEC-81| 950|null| 30|
| 7934|MILLER| CLERK|7782|23-JAN-82|1300|null| 10|
+-----+------+---------+----+---------+----+----+------+
>>>
Schema推論列印
>>> empDF.printSchema()
root
|-- _c0: string (nullable = true)
|-- _c1: string (nullable = true)
|-- _c2: string (nullable = true)
|-- _c3: string (nullable = true)
|-- _c4: string (nullable = true)
|-- _c5: string (nullable = true)
|-- _c6: string (nullable = true)
|-- _c7: string (nullable = true)
>>>

(起初先透過DataFrame暫存一個View)
使用empDF(dataframe)產生emp_tmptable(view),起初並沒有儲存定義於hive metadata。
使用empDF(dataframe)產生emp_tmptable(view),起初並沒有儲存定義於hive metadata。

>>> spark.sql('show tables').show()
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| default|sample_07| false|
| default|sample_08| false|
| default| web_logs| false|
+--------+---------+-----------+
>>> spark.sql('show databases').show()
+------------+
|databaseName|
+------------+
| default|
+------------+
>>>

>>> empDF.createOrReplaceTempView("emp_tmptable")
>>> spark.sql('show tables').show()
+--------+------------+-----------+
|database| tableName|isTemporary|
+--------+------------+-----------+
| default| sample_07| false|
| default| sample_08| false|
| default| web_logs| false|
| |emp_tmptable| true|
+--------+------------+-----------+
>>> spark.sql("select * from emp_tmptable")
DataFrame[_c0: string, _c1: string, _c2: string, _c3: string, _c4: string, _c5: string, _c6: string, _c7: string]
>>> spark.sql("select * from emp_tmptable").show()
+-----+------+---------+----+---------+----+----+------+
| _c0| _c1| _c2| _c3| _c4| _c5| _c6| _c7|
+-----+------+---------+----+---------+----+----+------+
|EMPNO| ENAME| JOB| MGR| HIREDATE| SAL|COMM|DEPTNO|
| 7839| KING|PRESIDENT|null|17-NOV-81|5000|null| 10|
| 7698| BLAKE| MANAGER|7839|01-MAY-81|2850|null| 30|
| 7782| CLARK| MANAGER|7839|09-JUN-81|2450|null| 10|
| 7566| JONES| MANAGER|7839|02-APR-81|2975|null| 20|
| 7788| SCOTT| ANALYST|7566|19-APR-87|3000|null| 20|
| 7902| FORD| ANALYST|7566|03-DEC-81|3000|null| 20|
| 7369| SMITH| CLERK|7902|17-DEC-80| 800|null| 20|
| 7499| ALLEN| SALESMAN|7698|20-FEB-81|1600| 300| 30|
| 7521| WARD| SALESMAN|7698|22-FEB-81|1250| 500| 30|
| 7654|MARTIN| SALESMAN|7698|28-SEP-81|1250|1400| 30|
| 7844|TURNER| SALESMAN|7698|08-SEP-81|1500| 0| 30|
| 7876| ADAMS| CLERK|7788|23-MAY-87|1100|null| 20|
| 7900| JAMES| CLERK|7698|03-DEC-81| 950|null| 30|
| 7934|MILLER| CLERK|7782|23-JAN-82|1300|null| 10|
+-----+------+---------+----+---------+----+----+------+
>>>
empDF=spark.read.format('csv').option('header','true').load('emp.csv')
DataFrame具有表頭的讀取寫法(兩種)
header=True:將第一行的值,以逗號當作分隔,當作欄位名字

>>> empDF=spark.read.format('csv').option('header','true').load('emp.csv')
>>> empDF.show()
+-----+------+---------+----+---------+----+----+------+
|EMPNO| ENAME| JOB| MGR| HIREDATE| SAL|COMM|DEPTNO|
+-----+------+---------+----+---------+----+----+------+
| 7839| KING|PRESIDENT|null|17-NOV-81|5000|null| 10|
| 7698| BLAKE| MANAGER|7839|01-MAY-81|2850|null| 30|
| 7782| CLARK| MANAGER|7839|09-JUN-81|2450|null| 10|
| 7566| JONES| MANAGER|7839|02-APR-81|2975|null| 20|
| 7788| SCOTT| ANALYST|7566|19-APR-87|3000|null| 20|
| 7902| FORD| ANALYST|7566|03-DEC-81|3000|null| 20|
| 7369| SMITH| CLERK|7902|17-DEC-80| 800|null| 20|
| 7499| ALLEN| SALESMAN|7698|20-FEB-81|1600| 300| 30|
| 7521| WARD| SALESMAN|7698|22-FEB-81|1250| 500| 30|
| 7654|MARTIN| SALESMAN|7698|28-SEP-81|1250|1400| 30|
| 7844|TURNER| SALESMAN|7698|08-SEP-81|1500| 0| 30|
| 7876| ADAMS| CLERK|7788|23-MAY-87|1100|null| 20|
| 7900| JAMES| CLERK|7698|03-DEC-81| 950|null| 30|
| 7934|MILLER| CLERK|7782|23-JAN-82|1300|null| 10|
+-----+------+---------+----+---------+----+----+------+
>>> empDF=spark.read.csv('/user/cloudera/emp.csv',header=True)
>>> empDF.show()
+-----+------+---------+----+---------+----+----+------+
|EMPNO| ENAME| JOB| MGR| HIREDATE| SAL|COMM|DEPTNO|
+-----+------+---------+----+---------+----+----+------+
| 7839| KING|PRESIDENT|null|17-NOV-81|5000|null| 10|
| 7698| BLAKE| MANAGER|7839|01-MAY-81|2850|null| 30|
| 7782| CLARK| MANAGER|7839|09-JUN-81|2450|null| 10|
| 7566| JONES| MANAGER|7839|02-APR-81|2975|null| 20|
| 7788| SCOTT| ANALYST|7566|19-APR-87|3000|null| 20|
| 7902| FORD| ANALYST|7566|03-DEC-81|3000|null| 20|
| 7369| SMITH| CLERK|7902|17-DEC-80| 800|null| 20|
| 7499| ALLEN| SALESMAN|7698|20-FEB-81|1600| 300| 30|
| 7521| WARD| SALESMAN|7698|22-FEB-81|1250| 500| 30|
| 7654|MARTIN| SALESMAN|7698|28-SEP-81|1250|1400| 30|
| 7844|TURNER| SALESMAN|7698|08-SEP-81|1500| 0| 30|
| 7876| ADAMS| CLERK|7788|23-MAY-87|1100|null| 20|
| 7900| JAMES| CLERK|7698|03-DEC-81| 950|null| 30|
| 7934|MILLER| CLERK|7782|23-JAN-82|1300|null| 10|
+-----+------+---------+----+---------+----+----+------+
>>>
DataFrame具有表頭的讀取且schema依資料自行推論
默認都會是string
inferSchema=True:欄位資料型態以推論方式決定
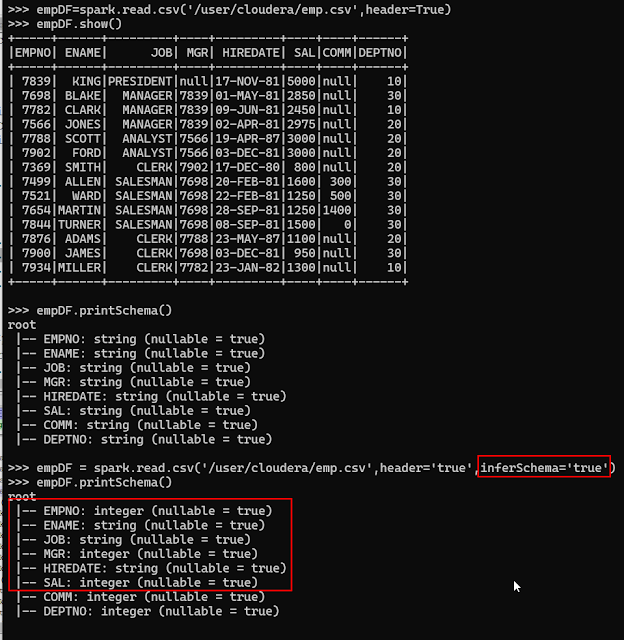
>>> empDF = spark.read.csv('/user/cloudera/emp.csv',header='true',inferSchema='true')
>>> empDF.printSchema()
root
|-- EMPNO: integer (nullable = true)
|-- ENAME: string (nullable = true)
|-- JOB: string (nullable = true)
|-- MGR: integer (nullable = true)
|-- HIREDATE: string (nullable = true)
|-- SAL: integer (nullable = true)
|-- COMM: integer (nullable = true)
|-- DEPTNO: integer (nullable = true)
>>>



留言
張貼留言