PySpark_命令與RDD使用(Transformation及Action)_深入筆記(二)_count()、sum()、reduce()、sortBy、sortByKey
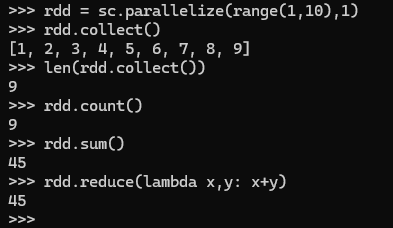
>>> rdd = sc.parallelize(range(1,10),1)
>>> rdd.collect()
[1, 2, 3, 4, 5, 6, 7, 8, 9]
將所有element傳回driver產生list物件,使用len(list)的到list的元素個數
>>> len(rdd.collect())
9
count()是action,統計元素個數後,回傳到spark driver顯示
直接在各個worker計算每個partition的元素個數,再傳回driver加總所有partition的元素個數
>>> rdd.count()
9
sum()是action,將 rdd的元素加總後,回傳到spark driver顯示
>>> rdd.sum()
45
>>> rdd.reduce(lambda x,y: x+y)
45
背後運行方式兩相鄰持續累加,在此用到lambda單行匿名函數。
[1, 2, 3, 4, 5, 6, 7, 8, 9]
x y
3
x y
6
x y
10
x y
15
x y
21
x y
28
x y
36
x y
45

>>> mydata = sc.parallelize(["the cat sat on the mat","the aardvark sat on the sofa"])
>>> mydata.count()
2
>>> mydata.collect()
['the cat sat on the mat', 'the aardvark sat on the sofa']
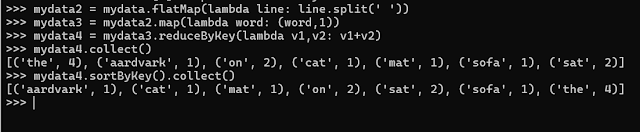
>>> mydata2 = mydata.flatMap(lambda line: line.split(' '))
>>> mydata2.count()
12
>>> mydata2.collect()
['the', 'cat', 'sat', 'on', 'the', 'mat', 'the', 'aardvark', 'sat', 'on', 'the', 'sofa']
>>> mydata3 = mydata2.map(lambda word: (word,1))
>>> mydata3.collect()
[('the', 1), ('cat', 1), ('sat', 1), ('on', 1), ('the', 1), ('mat', 1), ('the', 1), ('aardvark', 1), ('sat', 1), ('on', 1), ('the', 1), ('sofa', 1)]
>>> mydata4 = mydata3.reduceByKey(lambda v1,v2: v1+v2)
>>> mydata4.collect()
[('the', 4), ('aardvark', 1), ('on', 2), ('cat', 1), ('mat', 1), ('sofa', 1), ('sat', 2)]
>>>
>>> mydata4.saveAsTextFile('word_count')

[cloudera@cdh6 ~]$ hdfs dfs -getmerge word_count word_count.txt
[cloudera@cdh6 ~]$ pwd
/home/cloudera
[cloudera@cdh6 ~]$ ls -lt

[cloudera@cdh6 ~]$ cat word_count.txt
('the', 4)
('aardvark', 1)
('on', 2)
('cat', 1)
('mat', 1)
('sofa', 1)
('sat', 2)
上面結果沒有排序,完成了單詞頻率統計。
sortByKey
可以使用sortByKey()將結果排序
>>> mydata4.sortByKey().collect()
[('aardvark', 1), ('cat', 1), ('mat', 1), ('on', 2), ('sat', 2), ('sofa', 1), ('the', 4)]
sortBy(指定位置,排序方向->預設True表示為ascending由小到大)
以值由小到大排序
>>> mydata4.sortBy(lambda res: res[1]).collect()
[('aardvark', 1), ('cat', 1), ('mat', 1), ('sofa', 1), ('on', 2), ('sat', 2), ('the', 4)]
以值由大到小排序
>>> mydata4.sortBy(lambda res: res[1],False).collect()
[('the', 4), ('on', 2), ('sat', 2), ('aardvark', 1), ('cat', 1), ('mat', 1), ('sofa', 1)]

>>> mydata4.sortByKey().collect()
[('aardvark', 1), ('cat', 1), ('mat', 1), ('on', 2), ('sat', 2), ('sofa', 1), ('the', 4)]
>>> mydata4.sortBy(lambda res: res[1]).collect()
[('aardvark', 1), ('cat', 1), ('mat', 1), ('sofa', 1), ('on', 2), ('sat', 2), ('the', 4)]
>>> mydata4.sortBy(lambda res: res[1],False).collect()
[('the', 4), ('on', 2), ('sat', 2), ('aardvark', 1), ('cat', 1), ('mat', 1), ('sofa', 1)]
>>>



留言
張貼留言