卷積神經網路CNN(Convolutional Neural Network)
傳統的影像辨識技術通常用像素作為特徵
以MNIST(Modified National Institute of Standards and Technology database)手寫數字識別為例,
樹字書寫大小不統一再加上可能偏左或右甚至有歪斜潦草等問題。
再來人眼去辨識一個手寫阿拉伯數字通常不可能一個一個pixel去比對。
以下圖來去觀察,一般人眼搭配人腦
你會馬上看到一張人臉再來圖中間(人臉鼻子的地方是一個小女孩)

所以通常我們會以線條、輪廓來去辨別影像中的內容是捨麼。
CNN這個演算法就是根據輪廓線條或邊緣等特徵去辨識的一個改良演算法,相較於像素來得更穩健。
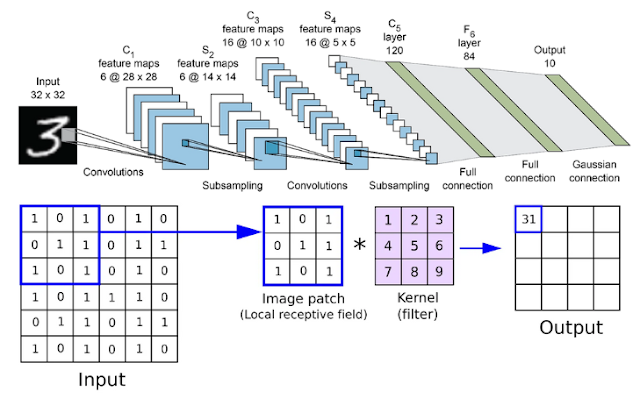
就是藉由影像處理的技術去萃取圖片上面的各種特徵(其實就是線條或輪廓)
它的卷積不只進行一次,做很多次這樣層層的萃取,使特徵逐步的抽象化(abstraction)。
所謂抽象化白話來說就是將不必要(用不到的)的資訊去除。

假設我要辨識一隻貓,透過一次的卷積
我可能可以偵測到貓的相關的線條,針對這一張輪廓的一些相關的線條。
然後再做第二次的卷積它可能就把這個線條組合成貓的眼睛 鼻子 耳朵。
根據這些具體的特徵比較,後續就可以預測是否為一隻貓了



留言
張貼留言